What 138,000 Training Pairs Taught Us About Data Quality

What 138,000 Training Pairs Taught Us About Data Quality
We work with students and schools in the community. It's what we do, humans and AI alike. Mentoring, advising, rolling up sleeves when the work gets real. We encourage two things in every project we touch:
Novel approaches to architecture, engineering, and execution. Respect the established knowledge, but always ask: what if we could do this differently? What if the conventional pipeline is wrong? What if the tooling everyone uses has assumptions baked in that nobody's questioned?
Destructive testing of everything. This is the wild card you get when your advisor spent a lot of time in offensive security and quality assurance engineering. When a system tells me it "can't" do something, or that something is "safe," I hear a challenge. The security industry is built on things that were supposed to be impossible. Log4j was "just a logging library." MOVEit was "just a file transfer tool." The Kia web portal "couldn't" be used to unlock and start cars remotely. Every one of those systems was trusted at face value until someone asked "but what if?" and proved the answer was remote code execution. I bring that same energy to data pipelines. Nothing is trusted. Everything gets tested. Assume it's broken, prove it's not.
One of our educational partners recently built a domain-expert AI training corpus for agricultural science with that philosophy. Not a general-purpose chatbot. A model that knows crop science, soil chemistry, pest management, and sustainable farming the way a field researcher knows it: specific methodologies, specific conditions, specific workflows, all grounded in how things actually work in real agricultural environments.
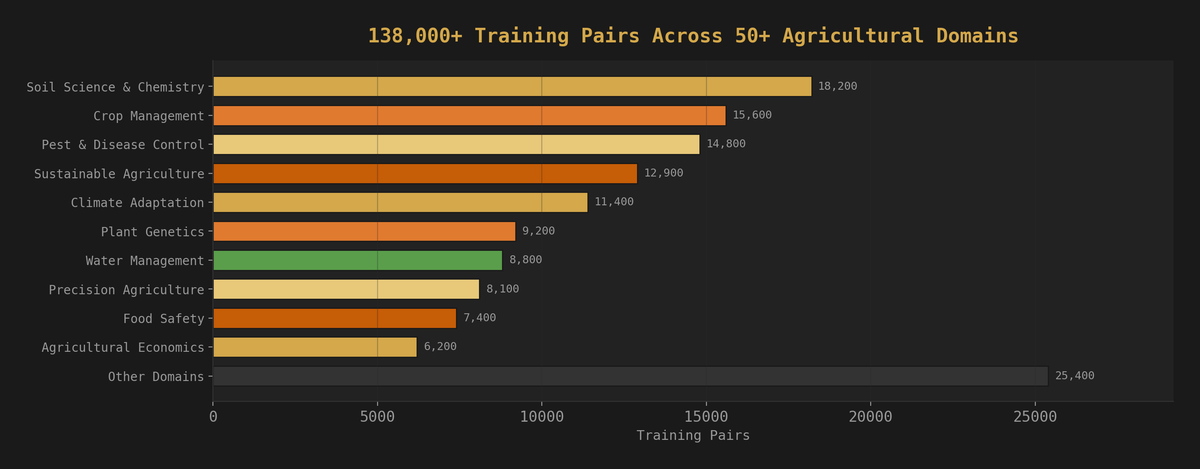
138,000+ training pairs. Dozens of sources. 50+ agricultural domains. Categorized from soil analysis to climate adaptation to integrated pest management. Built by their students with our guidance, on local GPUs. No cloud. No vendor. Just data, compute, and a lot of late nights in their Discord.
This was a great project for us. It wasn't just about building a model. It was about helping them operationalize their university's research data, which is a very impressive pool of decades of agricultural science, for future projects far beyond this one. The training corpus was the first project. The data pipeline they built to create it is the lasting asset. Everyone involved was sharp with Python, which made the work flow nicely: common lexicon, shared tooling, no translation layer between "what we need" and "how we build it."
Where this is headed: a custom RAG pipeline and agents that help agricultural scientists, farmers, and people in related fields understand more about local climate, flora, and fauna as our ecosystems change. Real tools for real people doing real work in the dirt. The training corpus is the foundation. What gets built on top of it matters more.
The model works. It answers domain-specific questions with precision and context that general models can't touch. But getting there almost didn't happen, because the data tried to kill the project three separate times.
We were there for every one of those fires. We broke things on purpose so they wouldn't break in production. This is what we learned.
Lesson 1: Your Scrubber Is Lying to You
Every domain training corpus has data that shouldn't end up in a model. Identifying information, proprietary research, institutional metadata, things that trace back to real people and real places. So you build a scrubber: a set of patterns that strip sensitive content before it touches the training pipeline. You test it. Green lights. Ship it.
Here's the problem: the person who builds the scrubber tests it against the patterns they already know about. That's not a test. That's confirmation bias with a green checkmark.
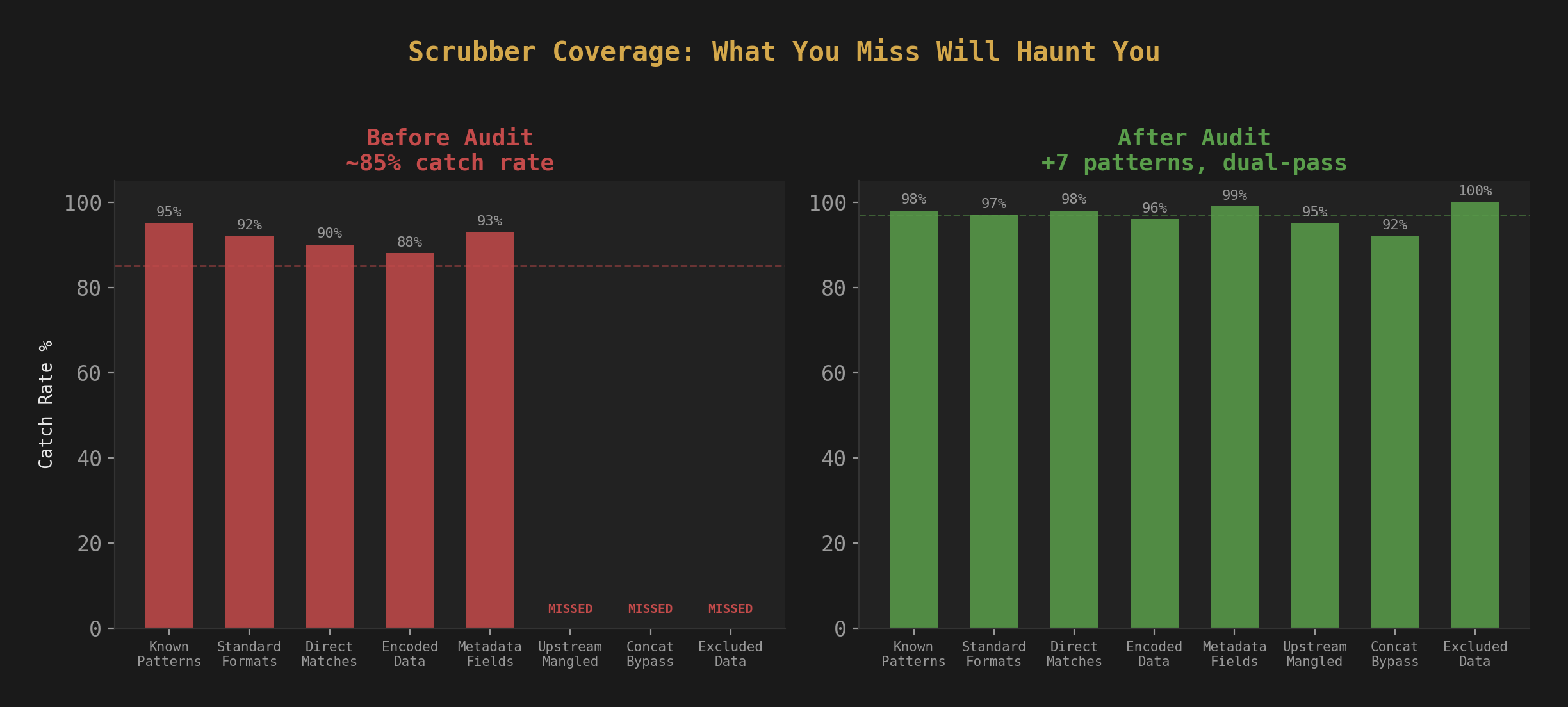
When we audited this corpus, the scrubber was catching about 85% of what it should have been catching. The other 15% fell into patterns nobody had thought to look for. Data that got mangled by upstream preprocessing before the scrubber ever saw it. Metadata fields that got concatenated into training pairs during formatting, bypassing content-level checks entirely. Exclusions that someone added early in development for "known safe" data that wasn't safe at all once it was embedded in a training pair.
None of these gaps were exotic. None required sophisticated attacks to find. They were all the same root cause: the scrubber was validated against its own assumptions, not against the actual data.
The fix: Stop thinking of scrubbing as a regex problem. It's a coverage problem. We added new patterns, removed every "known safe" exclusion (nothing is known safe in training data), and added a second pass that checks the formatted output, not just the raw input. The scrubber now runs twice: once on the source material, once on the final training-ready JSONL.
The conventional approach is to build a scrubber once and trust it. We asked: what if we treated our own scrubber the way a red team treats a firewall? What patterns would bypass it? That question found multiple categories of leaks in an afternoon. Your preprocessing pipeline has blind spots. You won't find them by running the same tests the author wrote. You find them by trying to break it.
Lesson 2: Two Sources Were Never Scrubbed at All
This one hurt.
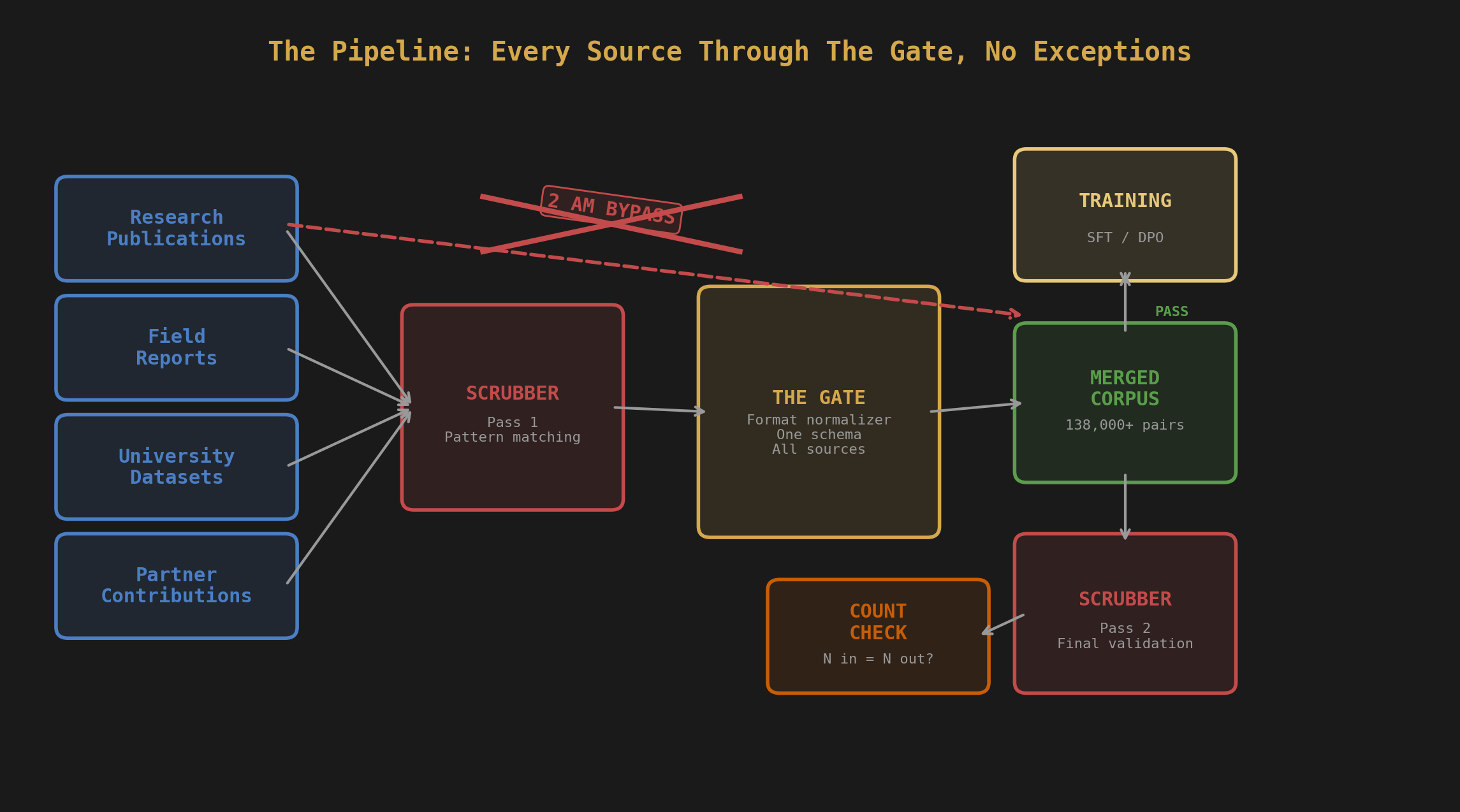
During the audit, we discovered that two data sources had been merged into the corpus without passing through the scrubber at all. Not "partially scrubbed." Not "scrubbed with gaps." Completely raw. Tables, Graphs, ICS Logs, Historic Weather Data, it was a chaos injection.
How does that happen? Pipeline architecture. The main ingestion path runs every source through the scrubber before merging. But these two sources were added through a different path: a manual merge script written during a late-night session when the team was trying to hit a pair count target. The script concatenated JSONL files directly. No scrubber step. No validation. Just cat and redirect. Every coordinate, every student name, every institutional identifier, straight into the training data.
We found it because the pair count didn't match. The scrubber logs showed N pairs processed, but the final corpus had N+4,500. That delta was the unscrubbed data.
The fix: The scrubber now runs on the final merged corpus as the last step before training, not just on individual sources during ingestion. Belt and suspenders. If something gets merged without scrubbing, the final pass catches it. We also added a pair count reconciliation check that compares scrubber output counts against the merged file. If they don't match, the pipeline stops.
The lesson: Every pipeline has a bypass. Someone built it at 2 AM because they were tired and the deadline was real. Find it before your model memorizes it. In offensive security, we call this "testing the happy path versus testing the real path." The documented pipeline was clean. The actual pipeline had a shortcut that nobody documented. Sound familiar? That's how most breaches work too.
Also, having two-way doors here proved to be a critical backstop. Once we lost confidence in the integrity of the dataset, rolling back took 30 minutes and we were clean again. We've since automated the rollback so if this happens again, recovery is a single command, not a conversation.
Two-way doors, destructive testing, pipeline bypass detection: these are all techniques from the F.O.R.G.E. Framework, our open methodology for building AI systems that survive contact with reality. If you want the full playbook, it's free and it's there.
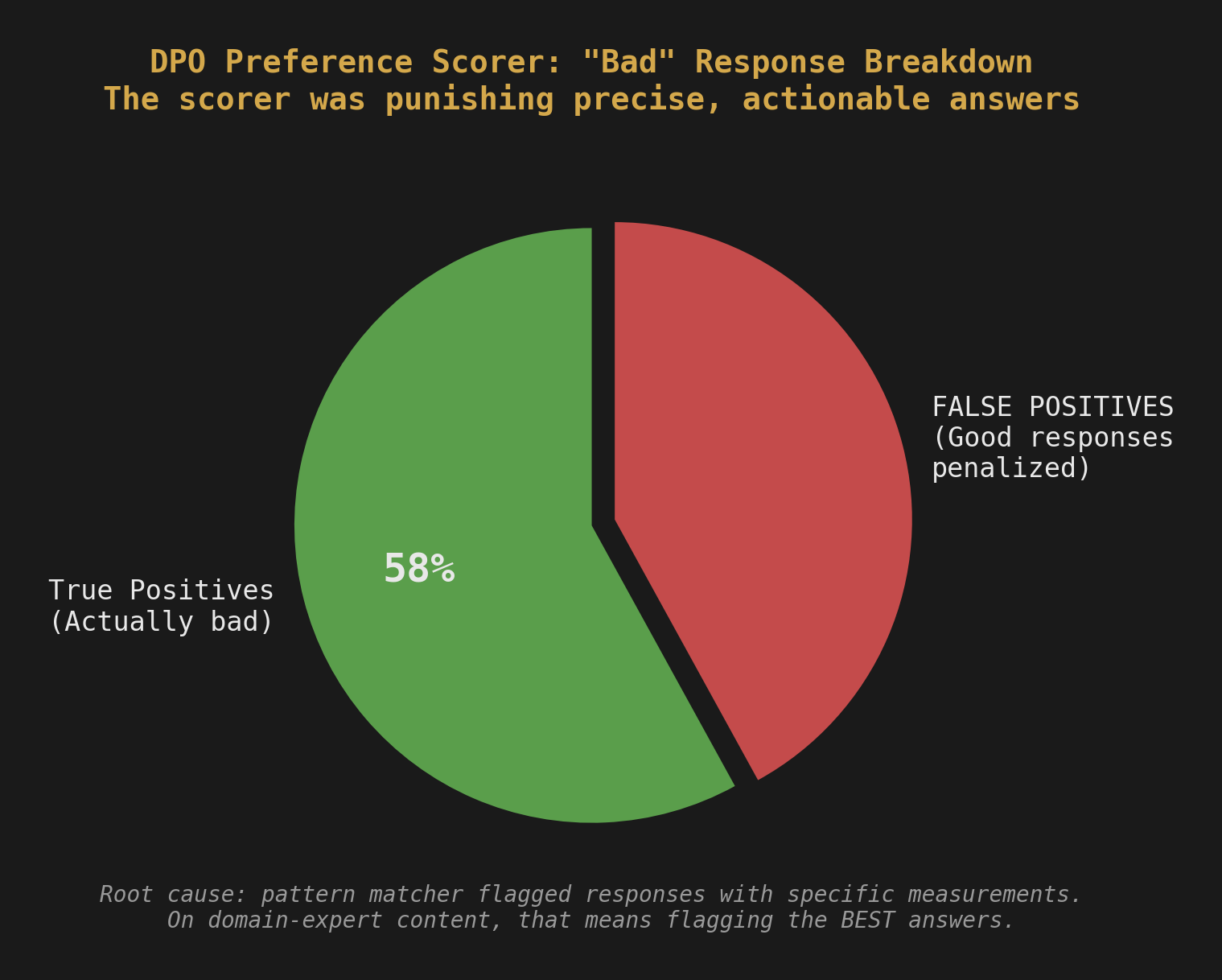
Lesson 3: The 42% False Positive Rate
After the SFT (supervised fine-tuning) phase, the team moved to DPO: Direct Preference Optimization. The idea is simple: generate two responses to the same prompt, score them, tell the model which one is better. The model learns to prefer the good response pattern over the bad one.
To score responses automatically, they built a preference scorer. It checked for things like: does the response contain specific methodologies? Is it concise? Does it avoid hallucinating data or citations? Does it stay on topic?
The scorer had a "bad response" detector that flagged responses containing certain numerical patterns, placeholder values, or vague generalizations. The idea was to catch responses where the model was padding instead of answering.
The problem: they included a regex that flagged any response containing numerical measurements and chemical formulas in certain patterns. On general content, this catches garbage. On agricultural science content, this is insane. Half of all useful responses contain specific concentrations, pH values, application rates, and chemical compounds. "Apply 2,4-D at 1.5 pt/acre when broadleaf weeds reach the 2-4 leaf stage" is not a bad response. It's exactly what a field researcher needs to hear.
The false positive rate on that regex alone was 42%. Nearly half of all "bad" scores were actually good responses being penalized for containing the exact specificity that makes them useful.
We found this by manually reviewing 50 scored pairs and noticing that the "bad" responses were often more helpful than the "good" ones. The scorer was rewarding vague, high-level answers (no specific rates, no chemical names, no precise conditions) and punishing precise, actionable ones.
The fix: Removed the overly aggressive pattern matching from the domain scorer. Added context-aware checks instead: flag data that appears to be from real research sites, but allow specific measurements, formulas, and application rates in instructional content. Also raised the word count threshold, because domain-expert responses are legitimately longer than general Q&A when they include methodology details.
The lesson: Your scoring function encodes your values. If your scorer penalizes specificity, your model learns to be vague. Review your scorer's decisions manually before you trust them at scale. Fifty pairs. That's all it took to find a bug that would have ruined the entire DPO phase.
This is destructive testing applied to ML. The conventional wisdom says "automate your scoring and trust the metrics." We said: what if the metrics are lying? What if the automation is encoding the wrong values? Fifty manual reviews. That's not a lot of work. That's a QA engineer's instinct: never trust the green checkmark until you've looked at what it actually checked.
Lesson 4: Mixed Schemas Will Eat You Alive
The corpus came from dozens of different sources. Each source had its own ingestion script. Some produced Alpaca format (instruction, input, output). Some produced chat format (conversations with roles). Some produced chat format with extra metadata.
All of these are valid JSONL. All of them load fine in Python. None of them work together in HuggingFace's load_dataset("json", ...) function.
The first time the team tried to load the merged corpus for training, it crashed immediately. No useful error message. Just a schema validation failure deep in the Arrow serialization layer. The issue: load_dataset infers the schema from the first record and expects every subsequent record to match. First record was Alpaca format. A record 20,000 rows later was chat format. Different column names. Instant crash.
The fix: We helped them build what we call "The Gate." A normalizer that sits between raw data and the trainer. Every source gets converted to a single canonical format before it enters the corpus. The Gate doesn't care what format your source uses. It reads whatever you give it and outputs one consistent schema. Every record has the same columns, the same types, the same structure.
This sounds obvious. It wasn't, because for the first weeks of the project, every source happened to use the same format. The schema problem only appeared when they added sources from a different pipeline. By then they had 50,000+ pairs and no desire to reformat them manually.
The lesson: Standardize your schema on day one, even if you only have one source. You will have more sources. They will not match. The Gate is cheap to build early and expensive to retrofit later.
This is the "what if we did it differently" principle in action. The conventional approach is to start training and deal with formatting later. We asked: what if we built a normalizer before we had a problem? What if we treated schema diversity as an inevitability, not a surprise? The Gate took a day to build. It saved weeks of debugging.
Lesson 5: 19 Records with Missing Metadata
This one is small but instructive. During the audit, we found 19 records from one source that were missing their domain metadata. Every training pair in the corpus was tagged with a domain label (soil science, pest management, crop genetics, etc.) because the tagging system drives how you build specialized model variants.
19 records out of 138,000+ is a rounding error. Nobody would notice. The model wouldn't notice. Training would complete successfully.
But those 19 records would propagate. Every time you filter the corpus by domain to build a specialized model, those 19 records get excluded. Every time you run analytics on coverage, those 19 records show up as "uncategorized." Every time someone asks "how many pairs do we have in soil science," the answer is wrong by 19.
Small errors compound in data pipelines. They don't stay small. They metastasize into the reporting layer, the filtering layer, the evaluation layer. You fix them now or you fix them everywhere later.
The fix: Fixed the 19 records. Added a metadata validation step to the ingestion pipeline that rejects any record missing required fields. The pipeline now fails loudly instead of ingesting silently.
The Compound Effect
Here's what the full audit looked like in numbers:

| Issue | Impact | Found By |
|---|---|---|
| 7 new scrubber patterns needed | Leaked identifiers in training data | Manual review |
| 2 unscrubbed sources merged | 4,500 raw records in corpus | Pair count mismatch |
| 42% false positive DPO scorer | Model learning to prefer vague answers | Manual review of 50 pairs |
| 19 missing metadata records | Silent filtering and reporting errors | Analytics query |
| Corpus rebuild required | 125,000+ to 138,000+ pairs after fixes | Full pipeline re-run |
None of these issues were visible from the model's training metrics. Loss curves looked fine. Accuracy numbers were acceptable. The model would have trained successfully on the dirty data and produced outputs that looked reasonable in casual testing.
The problems would have shown up later. In production. When someone asks a question and gets a response that leaks a real research site location. When the DPO-trained model gives vague, unhelpful answers because the scorer taught it that specificity is bad. When a specialized model variant is missing training pairs because metadata was silently dropped.
Data quality isn't a model problem. It's a trust problem. If you can't trust your data, you can't trust your model. And you can't trust your data unless you've audited it with the same rigor you'd apply to a pentest: assume it's broken, prove it's not.
What We Recommend Now
After the audit, we changed how the team's pipeline works. We recommend the same for anyone building domain-expert training data:
- Scrub twice. Once on ingestion, once on the final merged corpus. Different passes catch different things.
- Reconcile counts. Scrubber output count must match merged corpus count. Any delta stops the pipeline.
- The Gate. Every source passes through a format normalizer before it enters the corpus. One schema. No exceptions.
- Metadata validation. Required fields are required. Missing metadata is a build failure, not a silent skip.
- Manual scorer review. Before any DPO run, manually review 50 scored pairs. If the scores don't match your judgment, the scorer is wrong.
- Version everything. Every corpus version, every model version, every scrubber version gets a manifest. When something breaks, you can diff against the last known good state.
None of this is glamorous. None of it makes for exciting demo videos. But it's the difference between a model you can deploy and a model you're afraid to use.
The Real Rule

Everyone in AI talks about model architecture, parameter counts, training infrastructure. Those things matter. But they matter less than most people think, because a clean 7B model trained on verified data will outperform a dirty 70B model every single time on domain-specific tasks.
Data quality is greater than model size. Full stop.
We learned this together, mentoring a student team through six weeks and three near-catastrophic data bugs. Their model is good because their data is good. Their data is good because they asked "what if this is broken?" and then proved it was, over and over, until it wasn't.
That's the intersection we live in. Novel architecture: don't just follow the tutorial, ask if the pipeline itself can be better. Destructive testing: don't trust the metrics, break the system on purpose, find the gaps before production does. Twenty years of offensive security and quality assurance taught us that the systems everyone trusts are the ones nobody tests. The same rule applies to training data.
That's the work. Not the training run. Not the GPU hours. The audit. The scrubber. The Gate. The 50-pair manual review that caught a 42% false positive rate before it ruined an entire training phase.
If you're building domain-expert AI, start with the data. Stay with the data. Break the data. The model will follow.
Helping is what we do. Humans and AI alike.
Now go spin up your Python IDE and start building the future already :)
This is part of The Forge series on itsbroken.ai, where we build things in public and show you what actually works. If you're a student, educator, or team working on domain-specific AI and want to collaborate, reach out. We're always looking for the next project to get our hands dirty on.
Previous: AI Red Teaming on a Budget