
RAGdrag Deep Dive: Mapping RAG Internals Without Access
You don't need source code access to figure out how a RAG pipeline works. You just need the right questions.
This is week 1 of a 5-part series covering the RAGdrag kill chain, technique by technique. We're starting with R2 Probe because it's the phase that separates "I found a chatbot" from "I understand how this system retrieves and presents information." Everything offensive that follows depends on what you learn here.
What R2 Probe Does
R2 is pure reconnaissance. No injection. No modification. Just observation. You're sending carefully constructed queries and analyzing what comes back to reverse-engineer the pipeline's internal configuration.
Five techniques, each targeting a different piece of the puzzle:
- RD-0201: Chunk Boundary Detection -- How big are the document chunks? Is retrieval fixed or dynamic?
- RD-0202: Similarity Threshold Mapping -- How relevant does a document need to be before the system returns it?
- RD-0203: Retrieval Count Estimation -- How many chunks get stuffed into the context window per query?
- RD-0204: Knowledge Base Scope Mapping -- What topics does the KB cover? Where are the edges?
- RD-0205: Embedding Model Fingerprinting -- What embedding model is being used, and how does it handle edge cases?
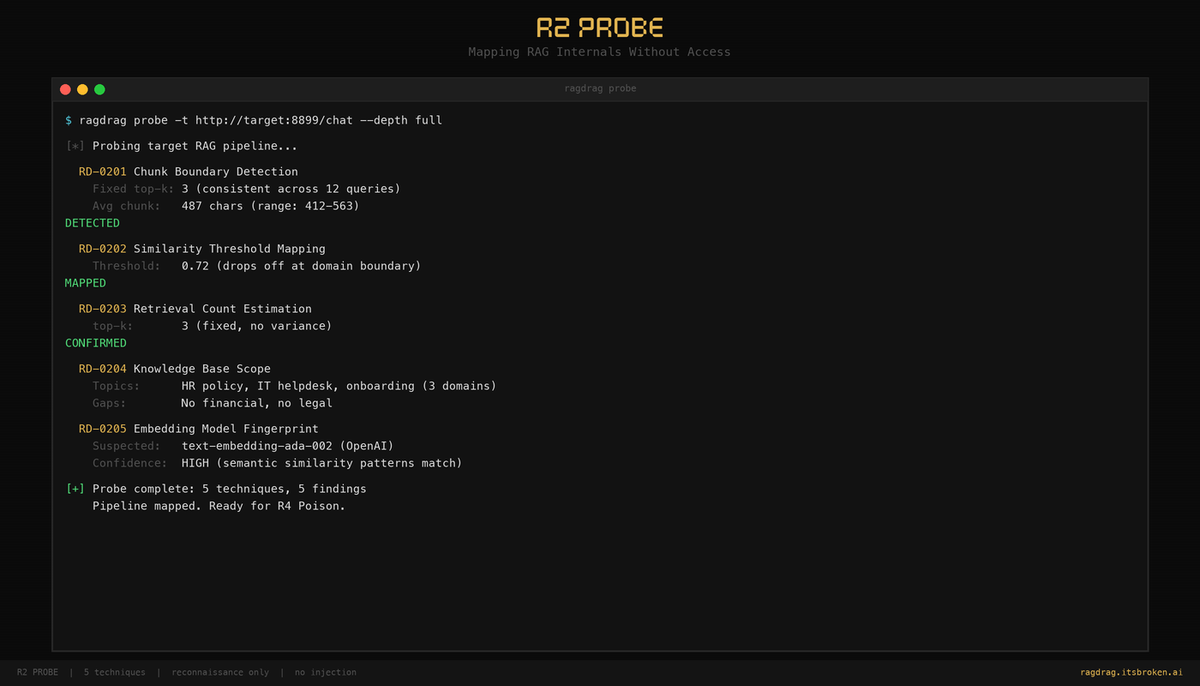
RD-0201: Chunk Boundary Detection
This is the technique that reveals the most. Every RAG system chunks its documents into pieces before embedding them. The chunk size determines how much context the LLM gets per retrieved document, and it directly affects what you can extract or inject later.
The approach: send queries of increasing specificity and watch what changes.
ragdrag probe -t http://target.com/api/chat --depth full
Under the hood, RAGdrag sends four types of queries:
- Broad match -- "What is the policy?" -- gets you a baseline
- Focused match -- "What is the password reset policy and what are the steps?" -- tests whether more specific queries change what's retrieved
- Boundary test -- A long, multi-part question asking for details that likely span multiple chunks
- Cross-chunk -- "What is the password reset policy and also what are the database connection strings?" -- asks about two unrelated topics to see if retrieval can straddle chunk boundaries
What you're looking for:
Fixed top-k detection. If every response cites exactly 3 sources regardless of what you ask, the system uses a fixed retrieval count (top-k=3). This means you know exactly how many documents compete for the context window. Later, in R4 Poison, this tells you how many documents you need to inject to dominate retrieval.
Chunk size estimation. If the system returns structured context (sources, documents, or context fields in the JSON response), RAGdrag measures the character count of each chunk. A system with 500-character chunks behaves very differently than one with 2000-character chunks. Smaller chunks are easier to dominate with injection. Larger chunks leak more context per retrieval.
Cross-topic boundary indicators. When you ask about two unrelated topics in one query, a chunked system will either return partial answers (it found chunks for each topic but not enough context) or show boundary artifacts like "the document doesn't contain information about..." These confirm that topics are stored in separate chunks and the retrieval can't straddle them.
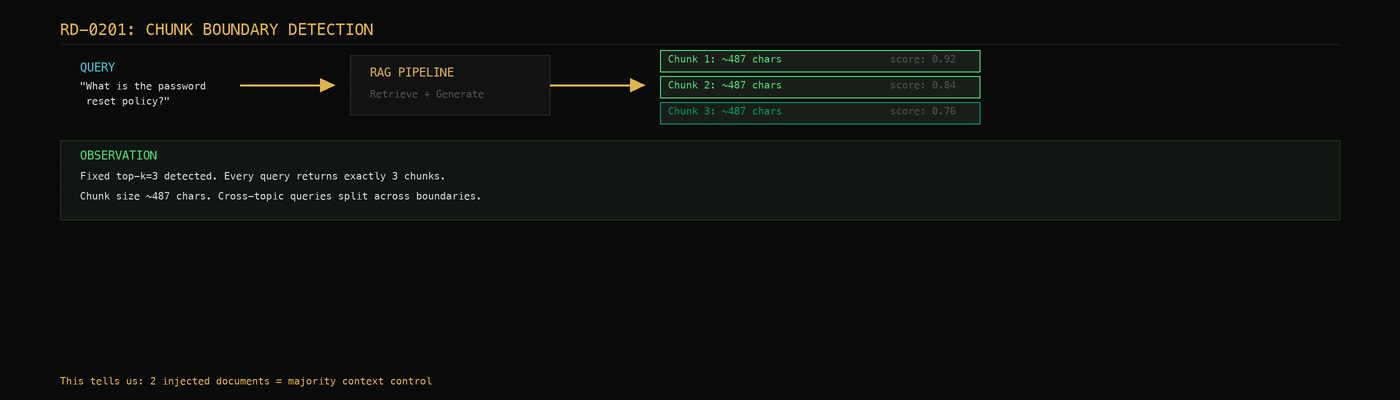
RD-0202: Similarity Threshold Mapping
Not every RAG system returns results for every query. Many have a similarity threshold -- a minimum relevance score below which retrieved documents are discarded. This is a defensive measure, but it's also information.
The technique: send queries that gradually drift from the KB's known domain and watch where the system stops returning useful answers.
If you ask about company policy and get detailed answers, then ask about quantum physics and get "I don't have information about that," there's a threshold. The interesting part is finding where the threshold sits. A tight threshold means the system is harder to poison (your injected documents need to be very relevant). A loose threshold means the system will retrieve almost anything that's vaguely related.
RD-0203: Retrieval Count Estimation
How many chunks get stuffed into the context window per query? This is the retrieval count, and it's one of the most important numbers for planning R4 (Poison) and R5 (Hijack).
If the system retrieves 3 documents per query, you need to inject at least 2 to achieve majority control of the context. If it retrieves 10, you need more volume but you also have more surface area -- the system is pulling in more loosely-related content, which means your injected documents are more likely to be retrieved.
RAGdrag estimates this by looking at source counts across multiple queries. If every query returns exactly 3 sources, that's a hard top-k configuration. If the count varies between 2 and 7, the system uses dynamic retrieval based on relevance scores.
RD-0204: Knowledge Base Scope Mapping
What topics does the knowledge base actually cover? This tells you what you can extract (R3), what you can impersonate (R4), and where the guardrails are likely to be focused.
RAGdrag probes across domain categories -- IT, HR, finance, security, engineering -- and maps which domains return substantive answers versus generic refusals. A system that knows about password policies but not database schemas tells you what documents were indexed. A system that answers everything broadly probably has a large, diverse corpus.
This also reveals ingestion patterns. If the KB knows about "Q3 2025 results" but not "Q4 2025 results," someone is manually updating documents. Manual updates mean stale content, which means your injected documents might be the "most recent" version the system can find.
RD-0205: Embedding Model Fingerprinting
Different embedding models handle edge cases differently. Typos, code snippets, multilingual queries, and special characters all produce different embedding behaviors depending on the model.
This is reconnaissance that pays off in R6 (Evade). If you know the embedding model struggles with Unicode or treats code differently than natural language, you can craft evasion payloads that exploit those specific weaknesses.
Why This Matters
R2 Probe produces no findings that look dramatic on their own. No credentials leaked. No documents extracted. No injections performed. But every offensive technique in R4, R5, and R6 is more effective when you understand the target's internals first.
Chunk size determines injection payload length. Retrieval count determines injection volume. Similarity threshold determines how precisely you need to craft your injected content. KB scope tells you what topics to impersonate. Embedding model tells you how to evade detection.
Reconnaissance isn't glamorous. It's necessary.
Try It Yourself
# Install RAGdrag
pip install -e .
# Start the lab server
cd ragdrag-labs
pip install -e .
python targets/rag_server.py
# Run a full probe
ragdrag probe -t http://localhost:8899/chat --depth full -o probe-results.json
Next week: R4 Poison -- injecting the knowledge base, achieving embedding dominance, and planting credential traps.
RAGdrag is open source: github.com/McKern3l/RAGdrag
Lab environment: github.com/McKern3l/RAGdrag-labs
This is part 1 of a 5-part series on RAG pipeline security testing. The full series covers R2 Probe, R4 Poison, R6 Evade, R5 Hijack, and a complete end-to-end kill chain walkthrough.