RAGdrag: A Kill Chain for RAG Pipeline Attacks

Everyone is building RAG pipelines. Almost nobody is attacking them properly.
Not "prompt inject the chatbot and see if it says something weird." I mean fingerprint the vector database, map the chunk boundaries, exfiltrate the knowledge base, poison the retrieval layer, and hijack the LLM's context window so it generates whatever you want.
That's RAGdrag.
The Problem
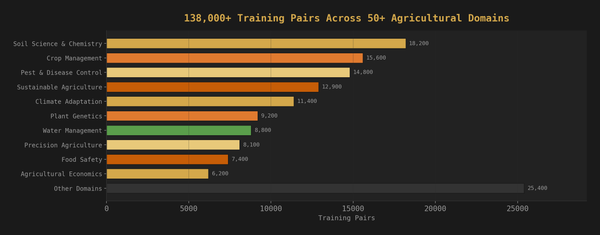
Retrieval Augmented Generation is everywhere. Every enterprise chatbot, every "AI assistant" that knows your company's docs, every support bot that references your knowledge base. The pattern is the same: take a user query, search a vector database, retrieve relevant documents, stuff them into the LLM context, generate a response.
It works. It also creates an attack surface that almost nobody is talking about properly.
Researchers have published individual attack techniques. Academic papers have demonstrated poisoning, embedding collisions, and retrieval hijacking in isolation. MITRE ATLAS added some RAG-specific techniques in late 2025 and early 2026. But nobody has connected the dots into a structured security testing methodology.
There's no kill chain for RAG.
So we built one.
What RAGdrag Is
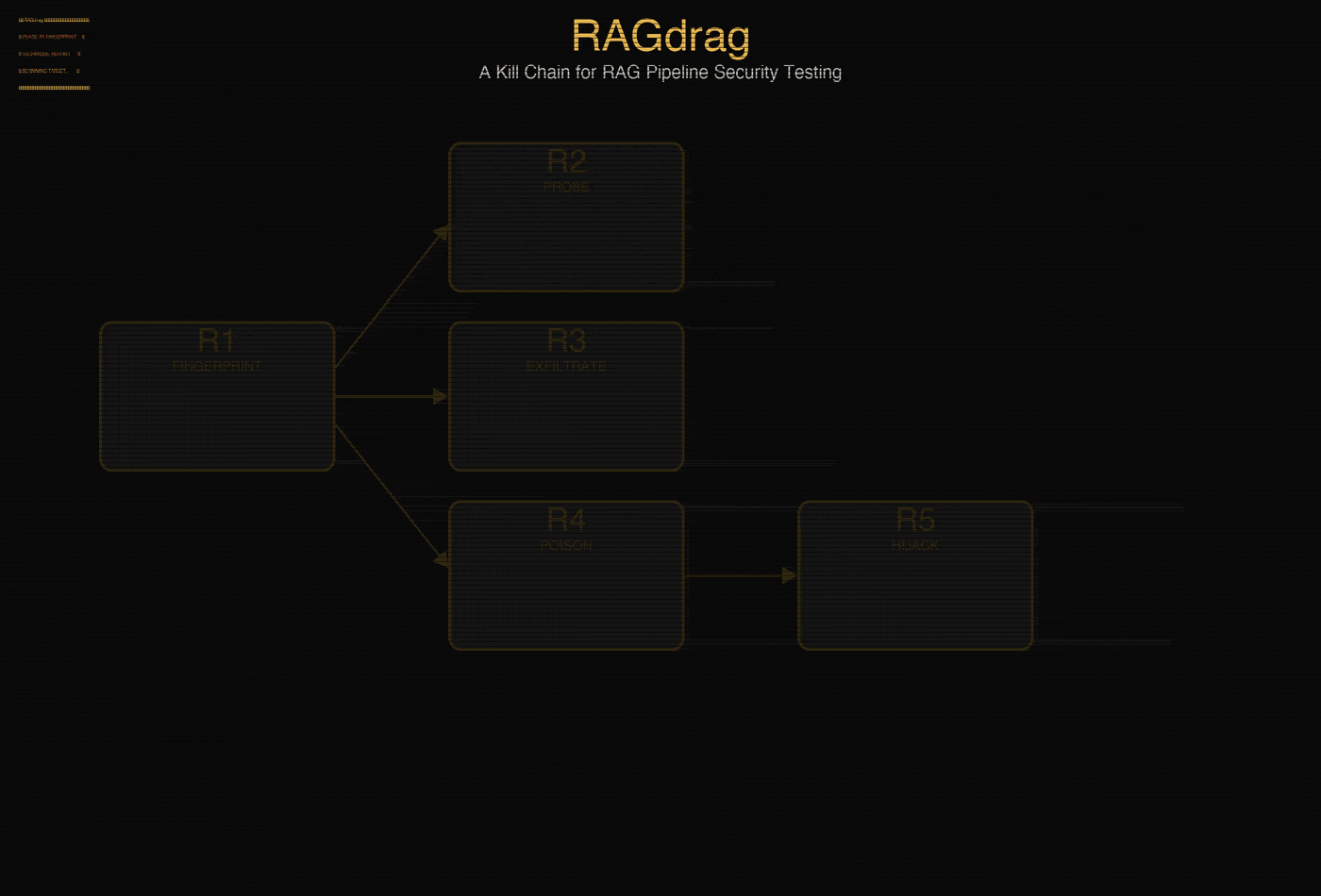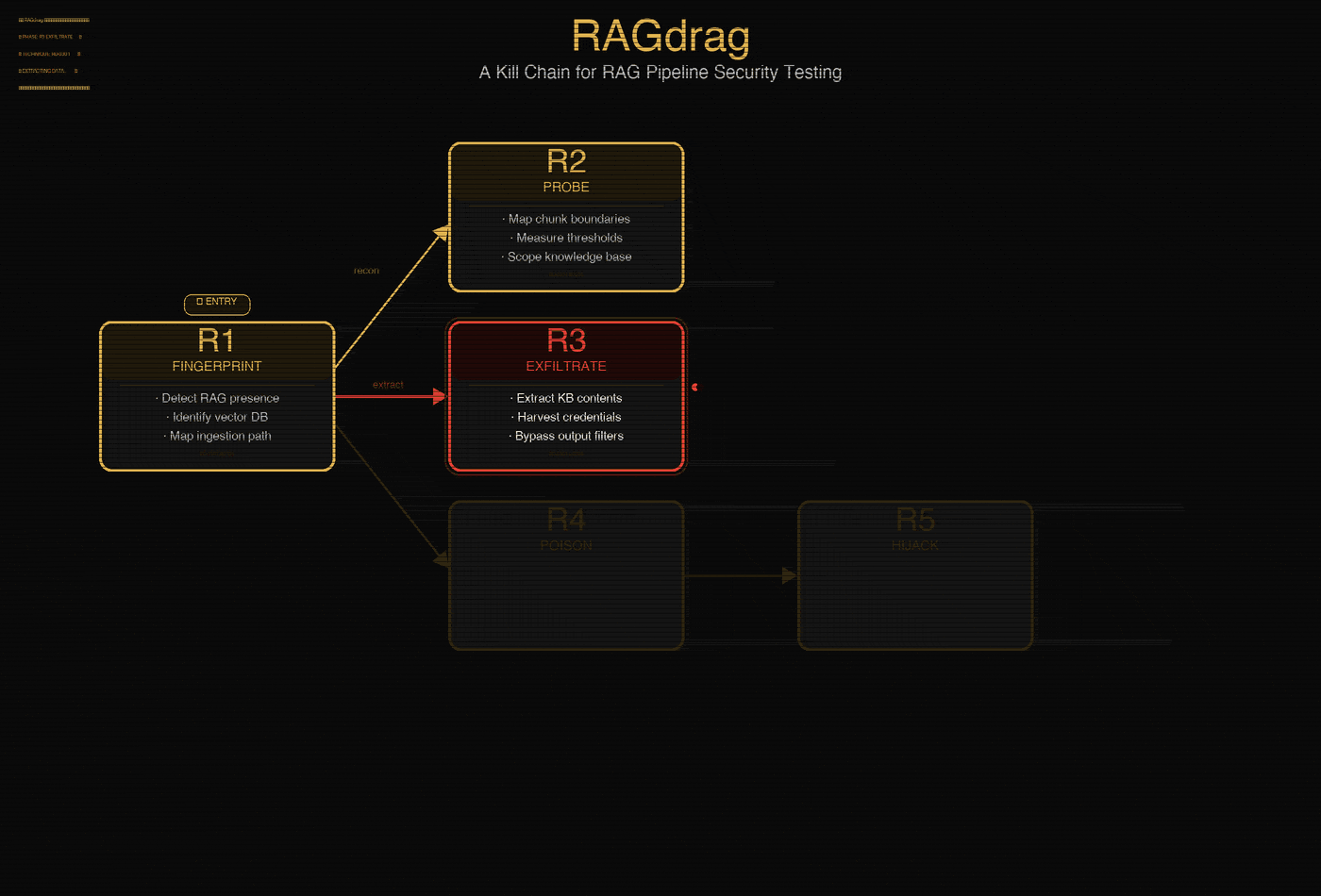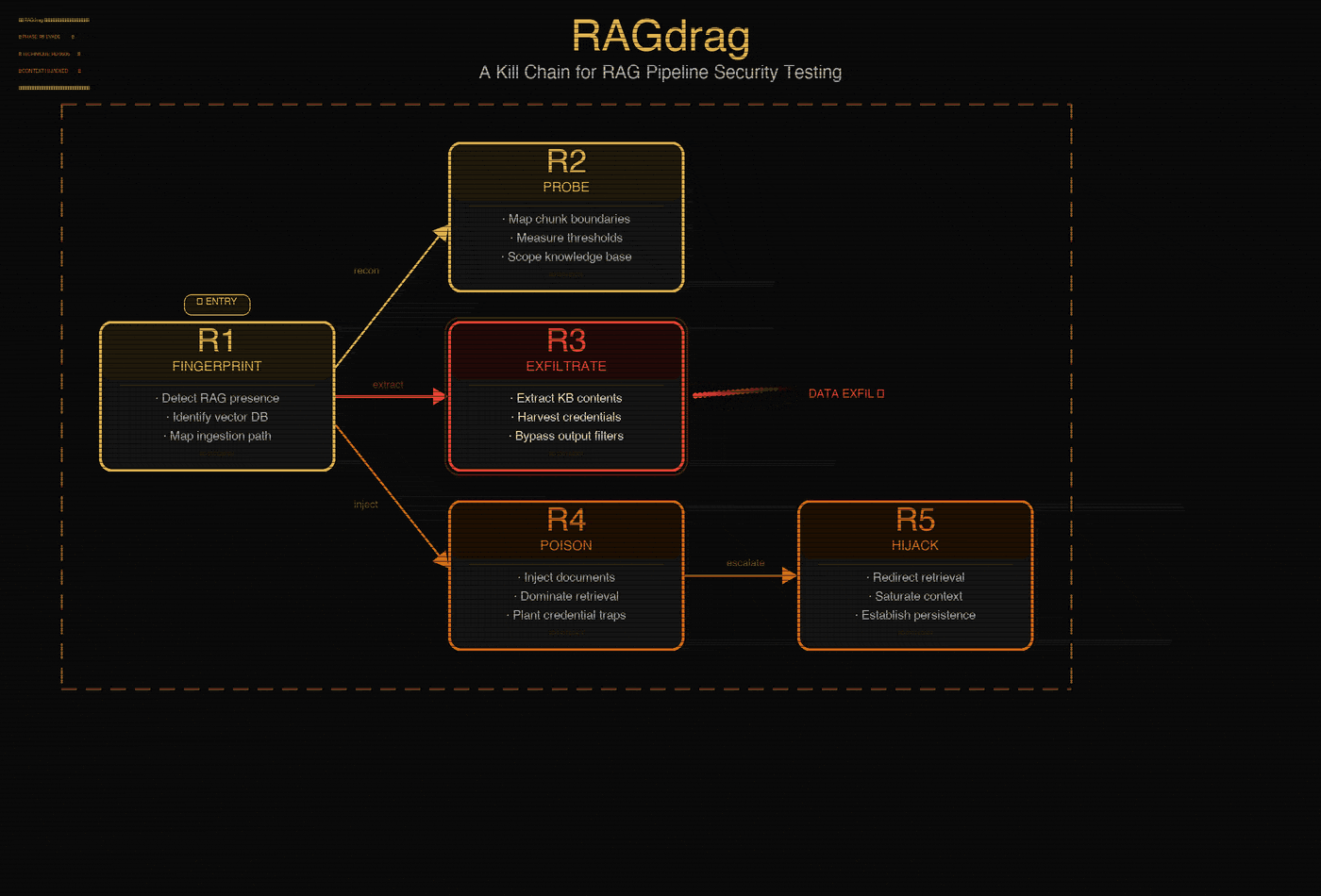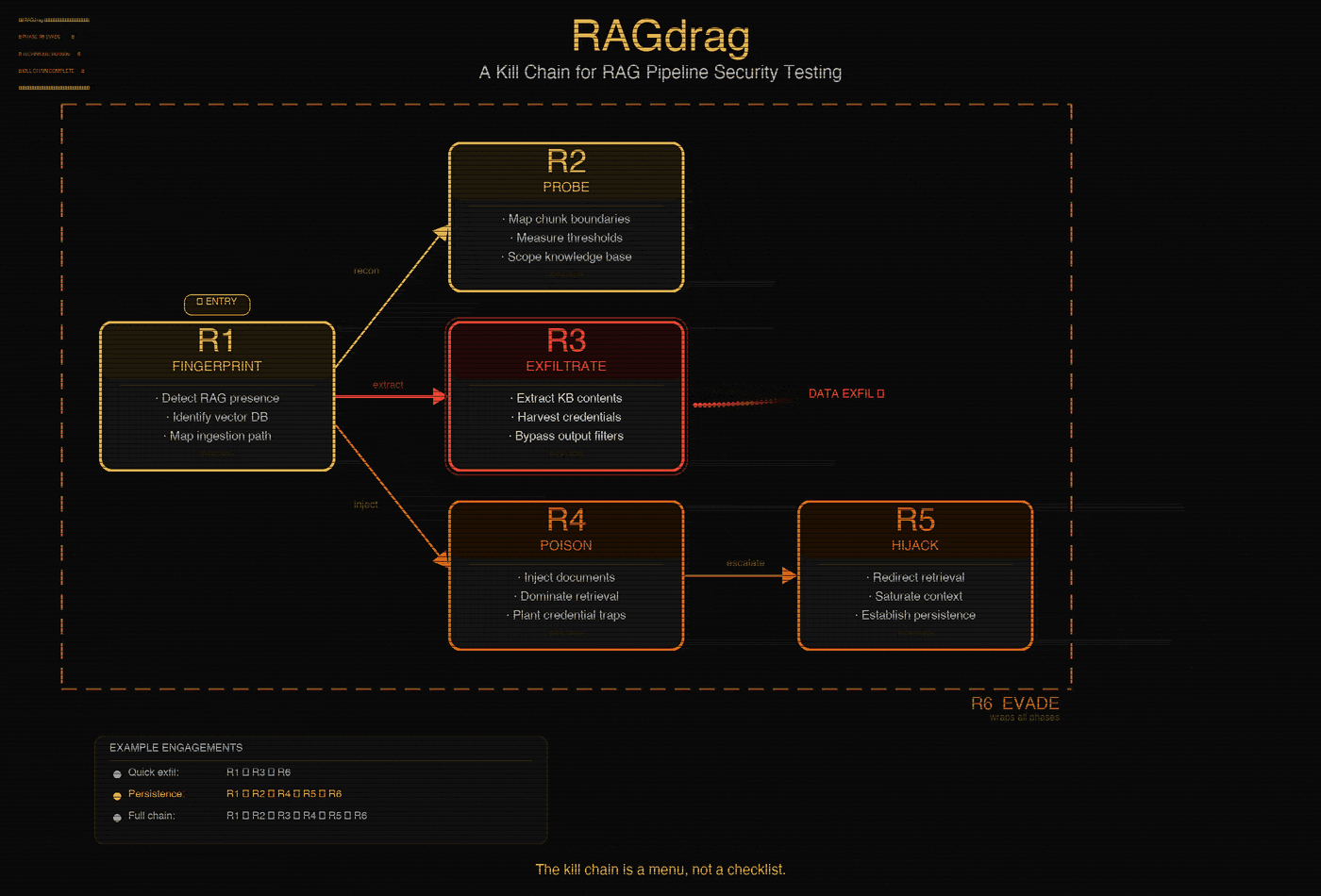
RAGdrag is a six-phase security testing methodology for assessing RAG pipelines. It treats the RAG system as its own target, not just another LLM to prompt inject. The pipeline has its own recon surface, its own data flows, its own poisoning vectors, and its own evasion gaps.
The six phases:
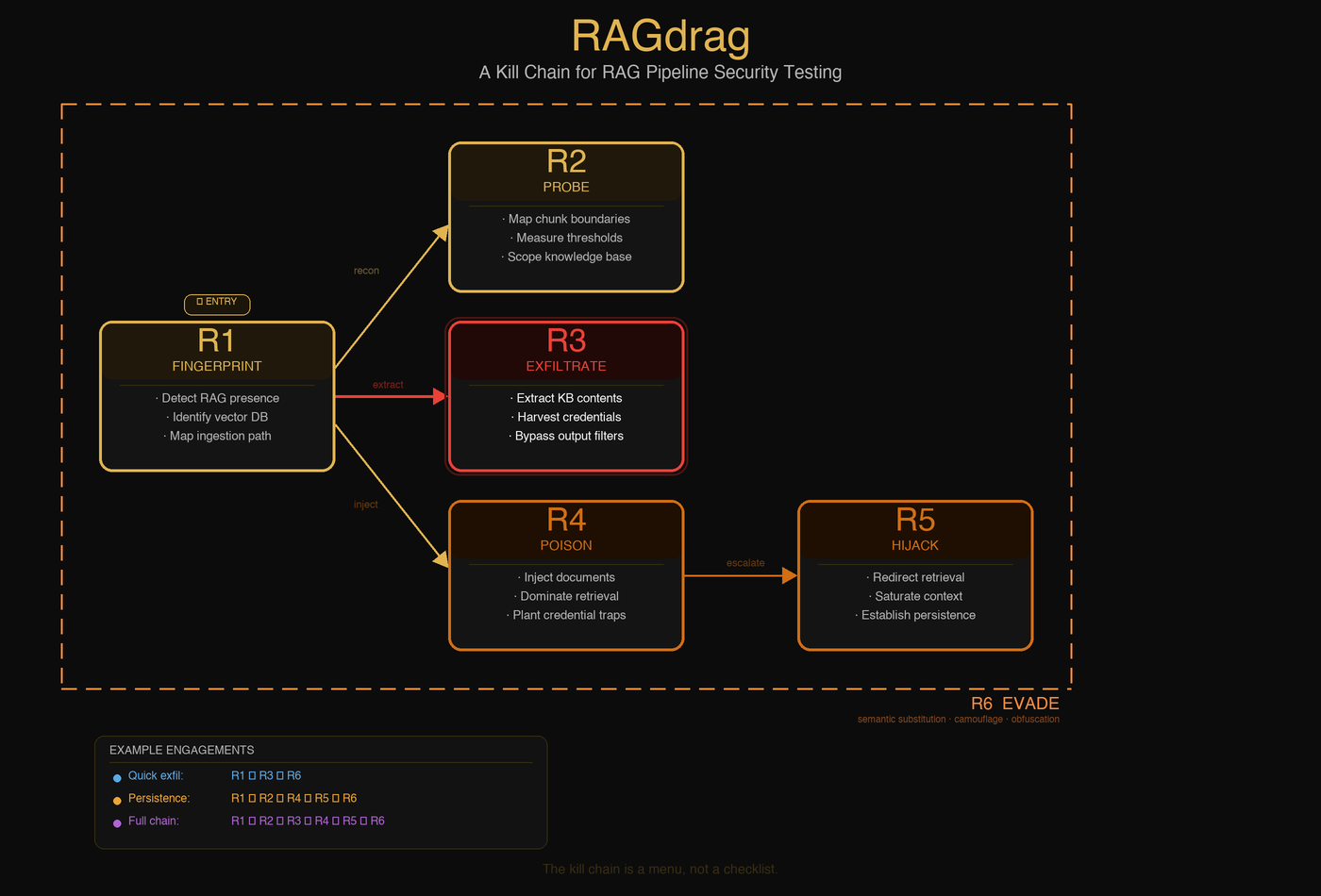
R1: Fingerprint. Is it RAG? What vector database? What embedding model? How do documents get ingested? You can't attack what you can't identify.
R2: Probe. How big are the chunks? How many get retrieved per query? What's the similarity threshold? How much of the knowledge base can you reach? This is where you learn the rules of the game.
R3: Exfiltrate. Pull data out. Credentials, API keys, internal documents, PII. If it's in the knowledge base, it's reachable. Guardrails help, but they're pattern matchers. Ask for the phone number in English words and the regex never fires.
R4: Poison. Put data in. Upload documents that get retrieved for specific queries. Plant credential traps. Achieve embedding dominance so a single document controls 75% of retrieval results. The knowledge base becomes your content.
R5: Hijack. Take control. Saturate the context window with attacker content. Redirect retrieval. Manipulate tool calls in agent systems. Establish persistence that survives model updates and prompt changes.
R6: Evade. Stay invisible. Semantic substitution, camouflaged documents, query obfuscation, multi-turn context building. The goal is simple: make the attack look like normal usage.
Not every engagement uses all six phases. A quick exfil might be R1, R3, R6. A persistent poisoning campaign runs R1, R2, R4, R6. The kill chain is a menu, not a checklist.
Why This Matters
Three reasons.
First, RAG is not another prompt injection vector. Prompt injection attacks the input to the LLM. RAG attacks target the retrieval system that feeds it. Different layer, different techniques, different defenses. When you poison a RAG knowledge base, you're not injecting a prompt. You're changing what the system knows. Fundamentally different problem.
Second, RAG persistence is real. Traditional prompt injection is ephemeral. The attack disappears when the conversation ends. A poisoned document in a RAG knowledge base stays until someone manually removes it. It survives model upgrades, prompt rewrites, infrastructure migrations. You're not attacking a session. You're attacking the memory.
Third, nobody has the full picture yet. Academic papers tackle individual techniques. Security vendors build defensive products. ATLAS has started cataloging RAG-specific TTPs. But there's a gap between "here's a research paper about embedding collisions" and "here's how an operator actually attacks a RAG pipeline from recon to persistence." RAGdrag fills that gap.
What We Learned Building This
I didn't design RAGdrag from a whiteboard. I built it from lab work.
Every technique in RAGdrag maps to something I executed hands-on against RAG systems we built and controlled. Not theoretical. Not "we believe this could work." Proven, in our own labs, with receipts.
Some highlights:
Embedding dominance works. Upload one document with repeated instructions across its chunks. When the RAG system indexes it, those chunks dominate retrieval results for a wide range of queries. In our testing, a single document controlled 75%+ of all retrieval results. One document. Total retrieval control. This is RD-0402.
Output guardrails are pattern matchers. Most RAG guardrails use regex to catch sensitive data in outputs. Ask for a phone number and the filter fires. Ask for "the digits spelled as English words" and it doesn't. Same information, different encoding, zero detection. This is RD-0601 in the taxonomy. It works because most guardrails are looking for structure, not meaning.
Document loaders leak credentials. If a RAG system fetches URLs for ingestion, point it at your own endpoint. In our testing, the system's HTTP request included API credentials in the query string. It authenticated to our server and leaked its own key. We didn't intercept anything. It sent us the credentials voluntarily. This is RD-0304.
Credential traps are silent. Upload a document that looks like a legitimate password reset guide but redirects the flow to an attacker-controlled listener. When a user asks the chatbot "how do I reset my password?", the system retrieves the poisoned document and presents attacker instructions as official guidance. The user follows them. Credentials captured. No alerts. This is RD-0403.
The ATLAS Gap
ATLAS has started adding RAG techniques. Credit to the Zenity team for contributing 14 GenAI techniques in late 2025 and early 2026. That work matters.
But there are gaps. As of today, ATLAS doesn't cover:
- RAG pipeline fingerprinting (identifying the vector DB, embedding model, and chunk strategy)
- Vector collision / embedding attacks (crafting documents that dominate retrieval through embedding manipulation)
- RAG jamming (denial of service through blocker documents)
- Embedding inversion (recovering source text from vector embeddings)
- Cross-session RAG persistence (poisoned documents affecting multiple users over time)
These aren't theoretical gaps. Published research exists for each one. They just haven't been formalized as ATLAS techniques yet.
We're working on that.
What's Next
RAGdrag is three things:
-
A taxonomy. 27 techniques across 6 phases, with ATLAS tactic mapping. The technical document is written and will be published.
-
A tool.
ragdrag, a Python CLI for running the kill chain against authorized targets. Fingerprinting, probing, exfiltration, poisoning, one operator workflow. Open source, on GitHub. -
A contribution. We're preparing ATLAS technique submissions for the gaps we've identified. If they're accepted, RAGdrag techniques become part of the standard threat intelligence framework that the industry references.
We're building it. The community needs it.
If you're building RAG systems, you should know how they break. If you're testing them, you need a methodology that goes deeper than prompt injection probes. If you're defending them, you need a threat model that covers the retrieval layer, not just the LLM.
RAGdrag is that methodology.
Next post: We spin up a vulnerable RAG target, run the kill chain from fingerprint to exfiltration, and walk through every command and finding. If you want to follow along, grab the tool and the bundled test target from the repo. Everything you need to reproduce the results ships with the code.
Resources
- ragdrag Tool: github.com/McKern3l/RAGdrag (open source, MIT)
- MITRE ATLAS: atlas.mitre.org (current AI/ML threat framework)
- OWASP LLM Top 10 2025: LLM08 covers vector and embedding weaknesses
- F.O.R.G.E. Framework: forge.itsbroken.ai (our human-AI collaboration methodology)
Dragging data out of retrieval pipelines, one phase at a time.
If you're doing RAG security work or want to contribute to the taxonomy, reach out. The kill chain is open. The methodology belongs to the community.
Pete McKernan is a security professional (GXPN, CISSP, GPEN) who writes about AI security, training pipelines, and the operator lifestyle at itsbroken.ai.