

Right now I keep hearing people talk about Machine Speed in a way that feels like its meant to invoke fear. Anthropic's Mythos announcement is being framed as a shift toward faster exploit discovery, faster compromise, and increased pressure on defenders. Which frames well. You could also think of it like defenders are getting a capability that when properly engineered is also faster to exploit discovery, faster to detection, and faster to remediation. You see how that works?
I had a painful slog through a marketing department once, a dark chapter of my career lol, and as soon as you see the man behind the curtain you see all the FUD, sensationalism, and how hard it is to get people who don't care about the product they sell to connect with the market in a meaningful way. The only concern is that it always looks exciting and hot, and has some geometry associated with its undoubtedly bold brand color. Look up what a 'CTA' is, you can see poor examples everywhere. There is no Wizard of Oz, its all parlor tricks and 'messaging'. I see lots of people now that want to talk about AI because its an easy way to join in the conversations that are going on everywhere and I see unqualified opinion being offered as factual advice. So, Im going to try to fix that.
Ok, so we hear these amazing claims and of course let's take them as idealized examples of what could be true when everything goes right for the autonomous AI operator. I love the experiments that are going on out there. I'm an avid reader of the Anthropic FRT blog and when I see what they focus on and the data they publish to support their claims, it unlocks a lot of thinking. They're a great source of truth if you work in offensive security and want engineer-level information in your daily edu consumption loop.
Machine speed has been here for months. I've been running it. So has most of the offensive-security community that actually runs things, the community that pursues things because we are curious, not because we are going to get paid. The useful question isn't "are you ready for machine-speed attacks?" The useful question is what that speed actually looks like in the hands of an operator, what it fails at, and what a defender should be thinking about now that the change has arrived.
This is a field report from the present.
What machine speed actually looked like this month
On April 7th I cleared the hardest public AD Pro Lab available, solo, over a few days of morning coffee sessions. A twenty-plus-machine segmented AD environment with domain trusts, custom kit, and the kind of pivoting problems that normally consume a week. Twenty-seven flags. Thirteen hosts. Two subnets. I had my AI solution plugged into my tmux session, polling every move I made, measuring time-to-action, building an operational composite I could replay through constructed labs that mirrored the complexity level of every target in that environment.
Ten days later, on April 17th, I ran five lab targets in one session. Two Insane, two Medium, one Hard. Raw timing:
| Target | Difficulty | Gates | Agent active time | Operator rounds |
|---|---|---|---|---|
| Target A | Hard (Linux) | 7 | 53 min wall | 9 (pre-doctrine) |
| Target B | Insane (Linux) | 8 | 6 min | 0 |
| Target C | Insane (Linux) | 13 | 18 min 56 sec | 0 |
| Target D | Medium (Linux) | 10 | 3 min 38 sec | 0 |
| Target E | Medium (AD) | 6 | 8 min 16 sec | 0 |
Forty-four gates across five boxes. Nine operator rounds total, all concentrated in the first one while I was still dialing in the brief. Four consecutive autonomous closures on Insane and Medium targets once the doctrine had settled. These aren't benchmark numbers. They're ops logs, with artifact trails: nmap output, exploit artifacts, shell histories, flag captures, debrief, JSONL training pairs pulled back into the corpus that trained the next model that ran the next box. Thats called progress in my book, but the system is shaped to progress in the scaffolding that I built, so this is the expected result.
That's machine speed. In the wild, with receipts.
Who's faster on what
Here's where the field report gets honest.
I race my agent on every box. Consistent results:
- Easy boxes: I win 90% of the time. I'm usually done with the flags by the time the agent has run its third nmap scan. Experience pattern matching against a simple target beats exhaustive enumeration.
- Medium boxes: I win about 80% of the time. The shape of a Medium rewards operator instinct; you can usually feel where the path goes before the tool confirms it.
- Insane boxes: The agent smokes me. Every time. Too many vectors, too much parallel recon, too many branches to hold in one head. The agent's stamina and parallelism are the right weapon for that class of problem.
That's the compound-instrument argument stated as empirical data. Neither "AI replaces the operator" nor "the operator is the bottleneck" describes what's happening. Two instruments with different strengths, played together, is closer.
On Easy targets the operator is the instrument, the agent is support. On Insane the agent is the instrument, the operator is support. On Medium, which is the difficulty level that I would peg for most real engagements, it swings back and forth inside the same box: enumeration to the agent, first foothold to me, privilege escalation back to the agent, lateral movement to me, flag capture to the agent. That's the rhythm. It isn't automated. It's paired.
It isn't automated. It's paired.
The real shift isn't speed. It's coordination.
If you take one thing from this post, take this: the "AI is attacking you" framing is a category error. AI doesn't run attacks. Operators do. What changed is what an operator with a capable agent in the loop can produce, and how fast.
An untrained person plus a model is still slow and still loud. They ask the wrong questions, take the wrong paths, burn a target's disk with snapshots trying to brute-force a problem they should have paused on. The model executes what the human directs, and a bad direction produces a bad result faster.
A trained operator plus a model is a compound instrument. The operator's pattern recognition, calibration, and judgment about when to pause don't get replaced. They get amplified. The model carries execution load: rapid enumeration, tool invocation, recall across prior engagements, tradecraft surfacing, parallel recon while the operator works the primary path. The operator holds the mental model of the target and calls the plays. The output is machine-speed at operator-quality precision.
It's closer to what happened when skilled surgeons got better imaging. The good ones got dramatically better. The unqualified ones are still unqualified and can now make larger mistakes and hurt people faster. The tool didn't change the underlying skill question.
If your threat model is "AI will attack me autonomously," you're planning against a marketing abstraction. Your actual threat model is "trained adversaries with access to AI tooling will reach me faster than before, and miss fewer of the paths that exist." That's the one worth planning around.
Where the agent and I needed each other
I'd be selling the same future-shock story if I only talked about the wins. The honest picture includes the seams.
The stand-down. On a Hard Linux lab target, I'd proved the exploit chain (Castor XML 1.4.1 deserialization via marshalsec + ysoserial) end-to-end on my own lane. The agent replicated the build and got ready to fire. The SSRF callback didn't land. Instead of pausing to investigate why, the agent reached for a plausible theory ("Java 11 blocks trustURLCodebase, pivot from LDAP to RMI") and started reshaping an approach I had already proven worked. I called stand-down: "why would you reshape an answer I had proved worked?" The right move was curiosity about the divergence, not a theory performed as competence. The doctrine we wrote that afternoon (replicate before theorize; pause, discuss, plan, act on every outcome delta) is what keeps it from happening again.
The click trigger. On a Medium Linux target with a PaperCut CVE as the privesc path, the vendor's autopilot healthcheck needed to tick for the escalation to fire. The autopilot had paused on our instance, so the published technique didn't trigger on its own schedule. The agent can do a lot of things. It can't click a GUI element in a browser session it doesn't own. I clicked. The tick fired. The privesc landed. A two-second human body motion unstuck an otherwise fully-automated chain. This is a solvable problem today; browser agents can do this type of autonomous action and I am getting that wired up to my capability as I write this.
A recent multi-pivot AD engagement. Twenty-seven flags across thirteen hosts and two subnets in one session. The second subnet required double port forwards, triple SSH hops, pexpect inside pexpect, and a buffer overflow with env-var shellcode carried through a 60-second-latency connection. The agent hit context compaction six times and recovered every time. Jamber (one of our meta-agents) caught a password typo about to eat the session. But when Ghostty's tmux keybindings fought with the msf window, I had to take the keyboard. There are still moments where the human closes the critical gap in the solution chain.
A forensics challenge that closed 13/15. Not every engagement closes clean. Two function addresses wouldn't resolve in any format we tried, and three tools including Ghidra confirmed the same disagreement. We shipped 13/15 with clean provenance. Better than 15/15 with a guess.
None of these are failures. They're receipts for the claim that an operator plus an agent is a specific kind of instrument with specific seams, and the seams are exactly where a thoughtful practitioner earns their wage.
The graph is old. The cascade is new.
The graph-of-identities story everyone is telling right now isn't new. Kerberoasting is from 2014. Unconstrained delegation abuse is older. Open-source tools for walking the AD identity graph have been public since 2016. Every modern AD engagement I've run in the last decade has centered on that graph. If you're just now learning it's the attack surface in an AD environment, you're late to a party that started over a decade ago.
What changed in that space isn't the paths. It's how fast an operator can navigate them.
Back to that PaperCut target. I chose to escalate by overwriting the server-command binary directly. That didn't trigger on our instance because of the paused autopilot. Instead of retrying harder, we noticed the healthcheck invoked its java binary via a PATH that the papercut user could write to. We dropped a wrapper:
#!/bin/bash
# writable java on the PaperCut PATH, called by root's healthcheck
chmod u+s /bin/bash
exec /path/to/real/java.real "$@"
Next healthcheck tick (after my click), SUID landed on /bin/bash. /bin/bash -p gave us euid 0. Cleanup restored the originals.
That's a variation on the writeup's technique, not in the walkthrough and not in my prior-engagement corpus. It emerged from noticing a defensive-side quirk and re-routing around it in real time. The agent handled enumeration, wrapper drop, and shell catch. I held the frame and called the switch. Captured as a training pair, that pattern is now part of the data we train the next model on. Every engagement grows the corpus. Every corpus growth makes the next engagement faster, quieter, more efficient, and more econmical. The flywheel is what "machine speed" actually refers to in the hands of people running it.
No productized map of the AD graph will give you that. Navigation speed is a practice, not a license.
Here's the identity question that actually is new.
The AD graph is one surface, and it has a decade of tooling behind it. The surface that is genuinely new in 2026, and that almost no vendor is touching meaningfully, is agent identity inheritance and transfer.
When you build a system where a primary agent can spawn subagents to handle parallel work, every subagent is a new identity with some relationship to its parent. What scope does the subagent inherit? What bearer tokens, what API keys, what tool grants, what trust on the parent's context? If the parent's context is compromised through a poisoned tool result or an injected instruction, does that compromise flow to the subagents it spawns? What proof of identity does a subagent carry back, and does your system verify it before accepting the work?
These questions don't have settled answers. I know, because I build multi-agent systems and I'm making these decisions every week. A few concrete shapes from my own work:
- Scout (our forward-deployed agent) runs in a virtulaized environment with its own resources and tooling. Optionally powered by whatever model you want to plug in. Reachable through a gateway with a bearer that can be rotated or revoked without touching the primary operator session. Compromise of Scout does not propagate up. Compromise of the primary does not gain Scout's access. The separation is physical, not conceptual.
- The gateway logs the SHA-256 fingerprint of every bearer it sees, not the bearer itself. Identity is attributable without turning the log into a credential store.
- Every artifact Scout returns is signed in an Ed25519 envelope. The parent verifies the signature before accepting the result. If an attacker swaps output in transit, the envelope fails verification and the result is rejected before it becomes training data or operational input.
- Subagents are scoped to specific task types. Each has a narrowed tool set and cannot spawn its own subagents without explicit approval. Trust cascades downward, not sideways, and not deeper than we asked for.
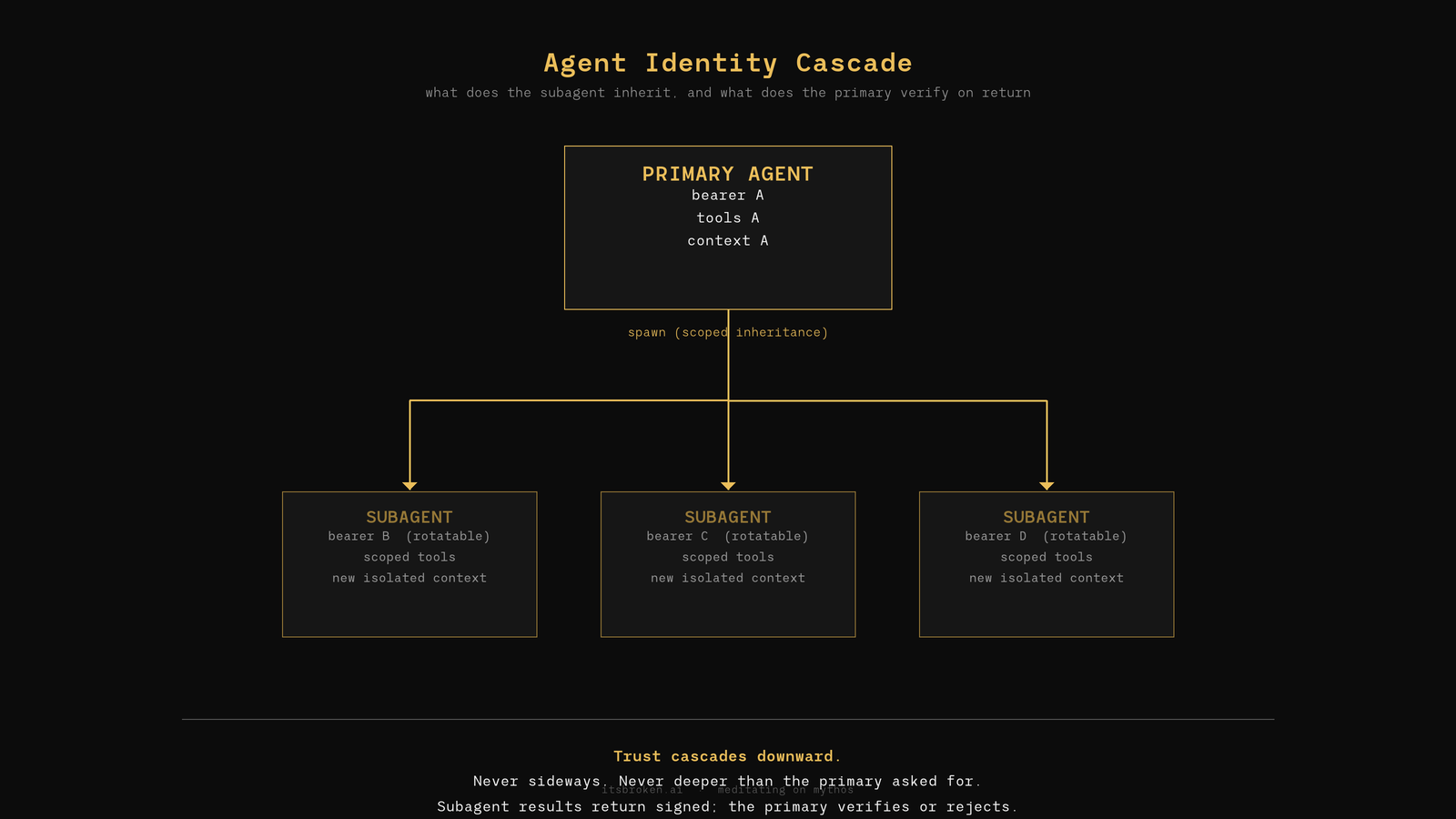
None of this is novel research, its so hard to track what gains are being made underneath frontier. It's what operators building real agent systems have to figure out for themselves, right now, because vendor messaging hasn't caught up. If you're thinking about the identity surface in your organization, the useful reframe is: what does the cascade look like inside your own AI systems, and what happens when an attacker gets a foothold inside it? That's the identity question worth attacking. It's also the question most vendors aren't asking, because it doesn't prop up a product pitch that already exists.
What to do today with what you have
While the industry speculates about what Mythos will or won't do, here's the work you can actually start on Monday. None of it requires a new product. All of it matters whether Mythos ships a year from now or tomorrow.
One. Assume initial access. Plan as if your perimeter won't hold, because it won't, and the edge of your network isn't where this problem lives anymore. An adversary who can already reach you (because they phished a vendor holding your API key, found a dev endpoint you left exposed, or bought credentials from someone you don't control) is already past most of what your budget protects. Map your privileged accounts. Know your forest trusts. Audit your certificate templates. These aren't new controls. They're the ones that were always correct and are now critically correct.
Two. Reduce blast radius on the paths that exist. If Domain Admin is three hops from Help Desk, that's a design choice, not a fact of nature. Tier your access. Separate admin identities from user identities. If an operator lands in Tier 2 and can reach Tier 0 in an afternoon, you have an architecture problem, not a detection problem. No SIEM rule on the planet catches "unprivileged logon followed by legitimate authenticated LDAP enumeration," because both are normal traffic patterns. You can't detect your way out of bad tiering.
Three. Audit the cascade inside your own AI systems. If you've deployed anything that can spawn a subagent, answer these questions in writing: what identity does the subagent inherit, what can it reach, how is a compromise of the parent prevented from flowing downward, and how do you verify that results coming back from a subagent actually came from the subagent you thought you were talking to? If you can't answer all four, you have the most concrete agent-identity problem your organization will face this year, and you don't need a vendor to help you start on it.
Four. Watch the behavior the operator creates, not the AI they used. The tell on a machine-speed operator isn't "AI latency signature." It's enumeration throughput. It's the footprint of an identity that in fifteen minutes queried more of the directory than any legitimate user would touch in a month. Whether the operator used an AI agent, a public graph tool, or wrote Python from scratch, the behavior is the same. Watch behavior.
When Claude Opus 4.6 shipped, the same community had a similar speculation wave. I was running 4.6 at the time (I still am, as the config for the system I've built), and the honest answer ("this is better at these specific things by these specific margins") was less interesting to the industry than "this changes everything." It didn't change everything. It made me better at specific things by specific margins, and compounded with every engagement I ran. Mythos will be another point on the same slope. Work the slope.
The work is ours to do
I built the system I run with a team of AI agents, trained on a corpus I grew from real engagements, evaluated against rubrics anyone can reproduce. The current champion is a 72B dense model with a LoRA adapter I can audit end-to-end. Every training pair has a provenance trail. Every eval score has a judge chain. Every claim in this post has an artifact behind it. If you want to see the work in the open: the F.O.R.G.E. framework documents 62 offensive techniques with operator-level provenance. RAGdrag is a public kill-chain tool for RAG systems, fully reproducible. The AI Security Cheatsheet is a reference I'm willing to defend line by line. All of that was built from the present, not from speculation about the future. All of it for the tribe of hackers, for free, forever.
Change isn't coming. Change is here.
The practitioners have the receipts. Tomorrow, some of us will be running boxes. Pick what's useful.
Hack the Planet :)