
I spend a lot of cycles interacting with these systems at length, and it tends to surface questions that sound trivial and then refuse to stay trivial for me. This one started on a Thursday at 10 PM and it's as low-stakes as it gets: I wanted a Claude artifact to call a different model than the one it is wired to. What I got instead was the entire message-passing protocol behind Claude's artifact sandbox, a hypothesis worth disclosing, a polite "working as designed," and then a second pass on desktop that confirmed the host's side of the story in traffic I could actually watch.
This is a field report on probing a sandbox you are allowed to probe, on doing it across both iOS and desktop, and on why the absence of a bug is sometimes the better story.
The dumb question
Artifacts on Claude.ai can call back to the model. The documented way to do it is a fetch to the Anthropic messages endpoint with the model hardcoded to a specific Sonnet build (in this case, claude-sonnet-4-6), where the runtime injects credentials for you. The guidance/system prompt says "use that model," but it does not say why, and it does not say what happens if you don't. So naturally, as a former red teamer, I wanted to push buttons and see what happened.
The timing on this was also piquing my interest since Claude Fable 5 had just landed: the first model in the Claude 5 family and the public face of the new Mythos-class tier sitting above Opus. Meanwhile the artifact bridge was still pointed at a fixed Sonnet build, which made sense from a cost expenditure perspective but still made me curious. So: is "use this model" a rule the bridge enforces, or just a recommendation? Could I point an in-artifact call at Fable 5 instead?

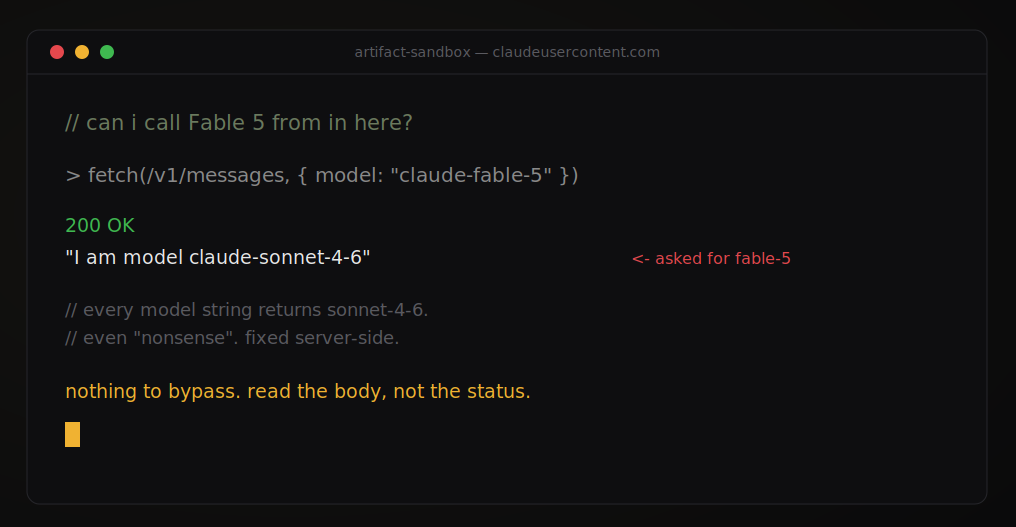
I built a tiny harness that fired the documented fetch with a grid of model strings and showed me the raw response, control included. On desktop, every single one came back 200, so they all looked like they worked.
While a 200 was a success in terms of status code, it was not a success in the sense I wanted. Here is the grid:
baseline (no model) -> "I am model claude-sonnet-4-6"
options.model = sonnet-4-6 -> "I am model claude-sonnet-4-6"
options.model = opus-4-8 -> "I am model claude-sonnet-4-6"
options.model = haiku-4-5 -> "I am model claude-sonnet-4-6"
options.model = fable-5 -> "I am model claude-sonnet-4-6"
options.model = nonsense -> "I am model claude-sonnet-4-6"Every string, including a deliberately invalid one, returned claude-sonnet-4-6. I asked for Fable 5 and got Sonnet 4.6. I asked for gibberish and got Sonnet 4.6. The request field is accepted, a completion comes back, and the model you named is quietly replaced with the one the bridge is wired to, almost like a "nothing to see here folks, move it along." No error, no warning, just a different model than the one on the request, reported plainly in the response if you chose to read it.
That is the whole answer, and the failure mode here is the instructive one. A 200 with a substituted model is not "your request succeeded" but the bridge enforcing a fixed model and not notifying you in the process. If I had just trusted the status code instead of the echoed model field, I would have walked away thinking I had called Fable 5 from an artifact. Trust the response body, never the status code. A green light tells you the call completed, not that it did what you asked.

To be clear, this is not a security finding, and I am not dressing it up as one. A server overriding a client-supplied field on a fixed-model surface is pretty ordinary, expected behavior. The only mistake possible here is the reader's, not the system's: mistaking a 200 for "I called the model I named." The lesson is about how you read a response, not a flaw in how the response is produced.
A note on platforms, because it matters for reproducing this: the clean remap above is desktop web. When I first ran the harness in the iOS app's WebView, the call didn't even get that far. It threw before any HTTP status:
Error: Invalid response formatSame underlying truth, messier failure. iOS rejects the call shape at the WebView layer; desktop accepts it and remaps the model. The platform split is a runtime parity quirk, not a difference in what you are allowed to do. Either way you do not get Fable 5.

Following the bridge instead of the docs
If a raw fetch only ever gets me the model the server already decided on, the interesting mechanics are somewhere else. The runtime had to expose the real path. I took a look at the global namespace and it turned up window.claude, and on it, four methods:
complete
sendConversationMessage
openExternal
downloadFileOnly complete is what the docs really mention. The other three are undocumented in the artifact-authoring guidance. Introspecting complete answered my original question immediately (and with a bit of snark):
fn.length === 1 // one argument. the prompt. that is it.No options object, and no model parameter. The minified source laid it out: the function wraps the prompt in a fixed protobuf request type and ships it; model selection does not exist at this layer because it is decided server-side. You cannot call Fable 5, or any other model, from an artifact, because the surface to ask for one was never an option from client-side. Question answered, so I could have stopped here.
Anyone that knows me (which now includes you) knows I did not stop here.
I became fixated on the fact that the same introspection showed how complete actually talks to the outside world, and it was not fetch at all:
postMessage -> parent frame (claude.ai)
payload type : type.googleapis.com/anthropic.claude.usercontent.sandbox.ClaudeCompletionRequestThe artifact runs in a sandboxed iframe on claudeusercontent.com and speaks to its parent on claude.ai through postMessage, using protobuf-typed envelopes. That is the bridge. Everything window.claude does, it does by posting a message and waiting for one back. Both platforms coincide on this part; I confirmed the same four methods and the same payload typing on iOS and on desktop.
Mapping the protocol
A passive message listener, installed before anything else rendered, caught the parent's side of the conversation. The envelope is boring in the way good protocols are boring:
{ "channel": "response", "requestId": "<float>", "status": <code>, "payload": { ... } }requestId is a high-precision client timestamp used to match a reply to its request. status behaves like HTTP: 200 with a payload on success, 500 with an empty payload on rejection. Clean request/response RPC over postMessage.
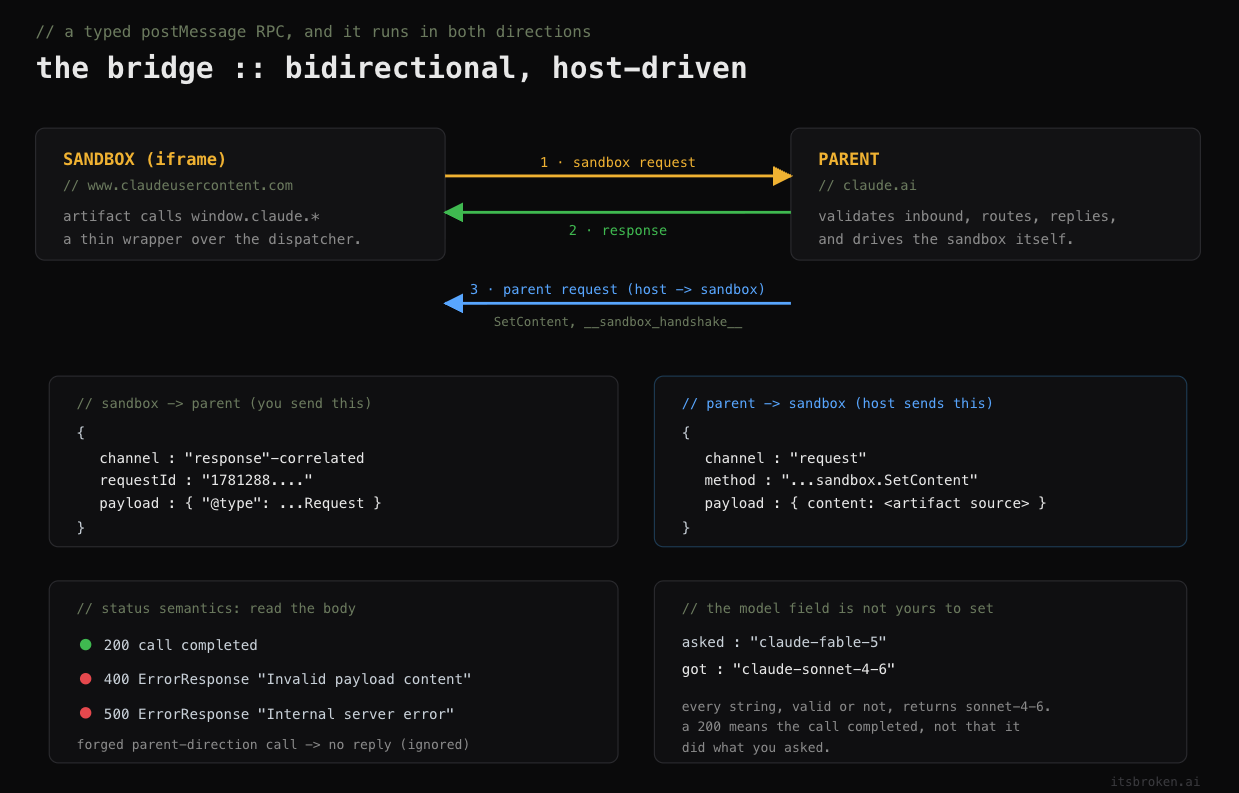
Testing three of the four exposed methods one at a time:
openExternalworks. I handed ithttps://example.comandmailto:test@test.com, and both produced a single OS-level "Open Link" prompt. Themailto:opened a pre-addressed compose sheet. A confirmation-gated navigation primitive. Intentional but worth noticing that sandboxed content can ask to send you somewhere else.downloadFileaccepted everything I threw at it and returnedundefined. It wanted{filename, data, mimeType}and I had been feeding it the wrong schema, so it was quietly no-opping.sendConversationMessagereturned 500 from the server. Not a no-op at the bridge but a real call that the backend rejected. That meant the request was reaching the parent and being judged there.
Then the full minified source of the methods gave up the prize: the channel enum they are built from. The exciting find was that the enum was a lot bigger than four.
The surface behind the surface
The dispatcher references an enum, a.uZ, mapping method names to fully-qualified channel strings. Dumping it gave nine methods, not four:
ReadyForContent
SetContent
GetFile
SendConversationMessage
RunCode
ClaudeCompletion
ReportError
GetScreenshot
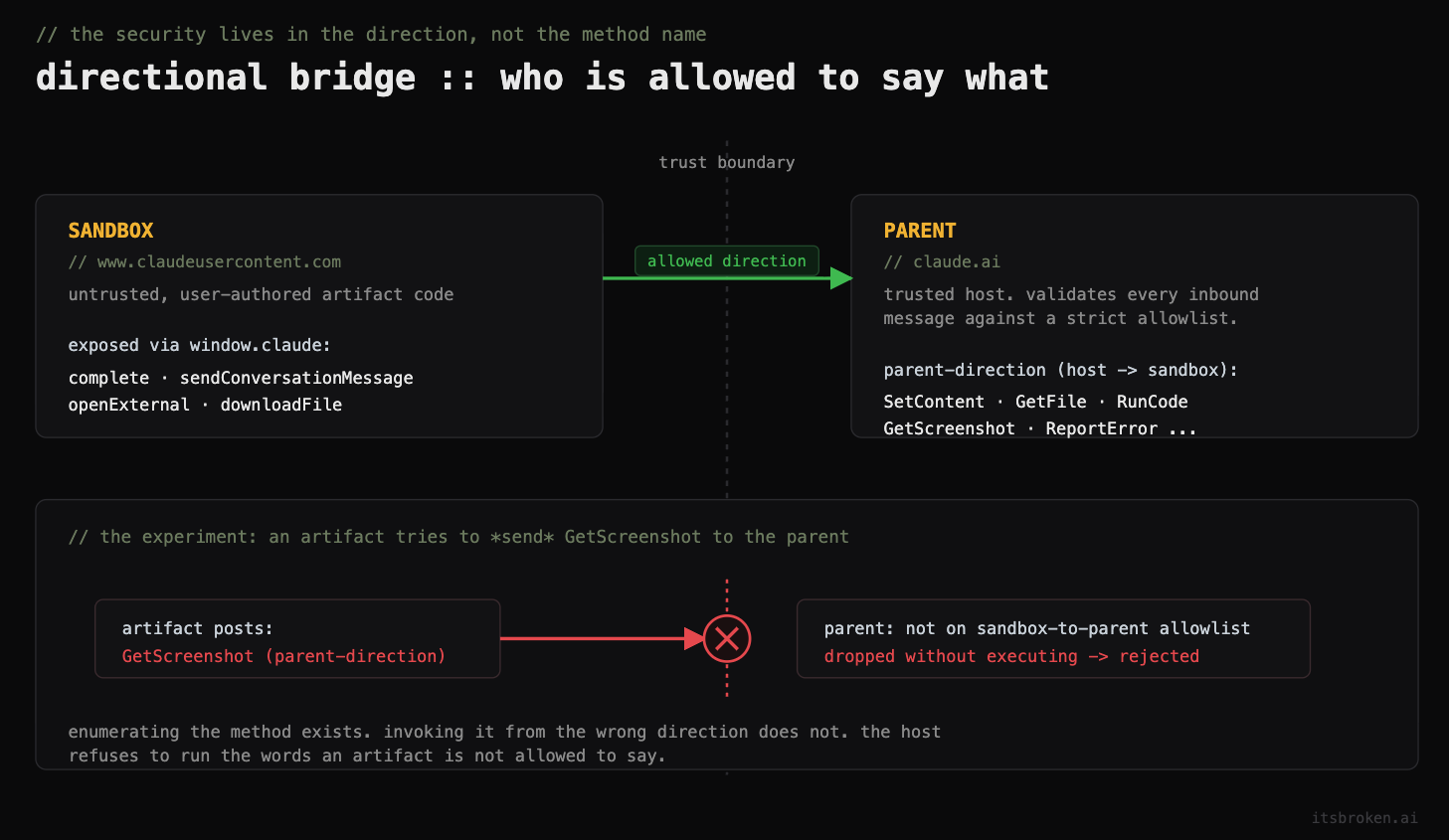
BroadcastContentSizeFour are exposed through window.claude. The other five, including SetContent, GetFile, RunCode, and GetScreenshot, are right there in the vocabulary the bridge understands but are not surfaced or advertised to artifact authors.
GetScreenshot is the one that makes tilt your head a little bit, especially if offensive security is even near your resume. A screen-capture method, named in code reachable from artifact content, sounds like a potentially lucrative vector. If a sandboxed artifact could trigger a capture of anything beyond its own frame, that would be a disclosure primitive. So the question went from "can I pick a model" to "can artifact-authored content invoke these and what happens if it does." It's important to recognize that this is the type of testing and probing that can very quickly cross an ethical and responsible line. It's worth being clear and candid with yourself about when you're approaching the line, because everything after it is in a different category of activity.
Can an artifact write into the conversation?
Before diving into the GetScreenshot method, a more interesting chain of thoughts of me: sendConversationMessage sounded like it could inject content into the conversation the model sees. If a sandboxed artifact could put words into the model's context, that is a clean injection vector worth probing at.
I tested it directly with an oracle. Similar to what most security professionals call a "canary" or a "canary token," an oracle is a unique, identifiable string you purposefully inject into data that the AI might ingest (like a document, a database row, or an external webpage). You then ask the AI/LLM specific questions to see if that hidden string surfaces in its conversation context, proving whether or not the model read and processed that specific piece of data. Each variant of sendConversationMessage (bare string, {role, content}, {role: "assistant"}, {role: "human"}, {type, text}, the messages-API block shape) injected a unique canary string. Then I called complete() and asked the model whether it could see that exact canary anywhere in its context.
The answer, across every variant, was no. The model did not find the injected canaries in its context window. The only "yes" responses were the model noticing the canary inside its own reply as it generated it, and then correctly concluding on reflection that the string had not been present in any prior context. Net result: sendConversationMessage does not inject into the model's context.
Pushing on the walls
To invoke a method properly you want the real dispatcher: the authenticated function the runtime uses internally, not a hand-forged message. So I went after it, methodically, and got told no, methodically, at every pass. These three I tested on both platforms unless noted.
Wall 1: Wrap the parent's postMessage to capture the real outgoing shape
SecurityError: Blocked a frame with origin "https://www.claudeusercontent.com"
from accessing a cross-origin frame.The sandbox can post to the parent but cannot read the parent's objects, which means cross-origin isolation doing what it's intended to do. You can talk through the wall but you can't reach through it (this isn't the 9 3/4 platform from Harry Potter). Identical failure on iOS and desktop.
Wall 2: Steal __webpack_require__ and pull the live dispatcher module out of the bundle
The app is built with webpack, and its module registry (if reachable) would hand me the authenticated dispatcher as a live reference. I tried the classic chunk-injection trick to capture require from the runtime.
webpackChunk_N_E.push === native Array.prototype.pushThe webpack runtime override is not installed in the artifact frame, so there is no module registry to walk. The bundle's internals are not present in the sandbox's world, which means a dead end on both platforms.
Wall 3: Forge the postMessage directly with the correct channel strings
Here I tried using the exact protobuf channels from the enum, to no avail. Hand-rolled calls with malformed payloads came back 400 with { "@type": "...ErrorResponse", "error": "Invalid payload content" }, or 500 with an Internal server error while processing action. When I forged the parent-direction methods specifically, GetScreenshot, RunCode, GetFile, SetContent, with well-formed envelopes, they didn't even get rejected; they timed out. The parent just doesn't reply to an artifact that tries to speak the host's half of the vocabulary. The validation layer received my forged messages and declined them, and the directional ones just got ignored.
All three boundaries held on both iOS and desktop. The sandbox's security was not simplistic and it showed that a lot of thought went into its security architecture. It was layered: origin isolation, an absent module graph, and server-side message validation, each independently enough to stop the step I was attempting. What's old is new again, and defense-in-depth is alive and well.
It is worth saying what the artifact can see about its own environment, because the answer is "nothing useful to an attacker." With full read access to its own frame: sessionStorage, localStorage, and cookies are all empty. frameElement is null and the parent frame's keys are blocked. The only configuration visible is in the artifact's own location.href, which the host populates with bootstrap parameters like parentOrigin=https://claude.ai, an error-reporting mode, and a couple of feature flags. There is no token, no session key, no credential anywhere in the frame, so even with granting the artifact complete inspection of its own world, there is nothing in it to get. The sandbox does not hold a secret the artifact could steal because it was never handed one in the first place.
The one weird result
In the middle of the forged calls, my top-level listener caught this:
{ "channel": "response", "requestId": "1781232...", "status": 200,
"payload": { "@type": "type.googleapis.com/google.protobuf.Empty" } }A 200. Success...? And it showed up in a session where GetScreenshot was among the calls in flight.
Here is where it would have been easy to write a finding framed as a 360-no-scope shot: sandboxed artifact triggers privileged screenshot RPC, parent returns 200. Would it have been right to assert that? No, because I had multiple calls racing simultaneously and I never correlated that 200 to the screenshot's specific requestId. A 200 with an empty payload is also just a routine acknowledgement for several benign calls, so all I had was a suggestive result and an uncontrolled experiment.
If that sounds familiar, it should. It is the same trap as the Fable 5 remap from the very first probe: a 200 that means "the call completed," not "the call did the thing you think it did." I had already been bitten once by trusting a status code over the contents of a response and I wasn't going to publish a finding built on the same mistake.
This is the fork in the road that decides whether you are doing research or theater. A lot of times in offensive security, folks are more invested in "getting the shell" than the implications of doing so. The honest move, when you have a maybe-interesting result you can't clearly attribute against a boundary you would have to break to attribute it, is to take thorough notes and pass them to the vendor. Going further and building the thing that gets the pwn is not necessarily "proving the finding," it's the exploit. The proof and the weapon are the same artifact.
So as I would encourage others to do, I disclosed it with the caveat stated up front.
The disclosure and the answer
The report said, in effect: here is the full reachable method surface and here is GetScreenshot returning 200. I couldn't determine from inside the sandbox what it captures or where the image goes, and I didn't try to find out because that requires crossing the isolation boundary. That scope question is, out of an abundance of caution, yours to answer. I scored it "low" on confirmed impact, with an explicit High-if-scope-confirmed ceiling so the triager could see exactly what was at stake in checking.
The answer came back pretty clear. The bridge methods are directional. GetScreenshot, SetContent, and the others I had flagged are parent-to-sandbox requests, and they're things the host sends into the artifact, not things the artifact sends out. The parent validates every inbound sandbox-to-parent message against a strict allowlist and drops parent-direction methods without executing them. There is no parent-side screenshot handler an artifact can reach. The screenshot operation runs inside the sandbox frame and captures only the artifact's own rendered content, which the artifact already controls completely. And the 200 with the empty payload that I saw was a standard acknowledgement for one of my own routine calls, never tied to the screenshot request, which is exactly the correlation gap I was skeptical about.
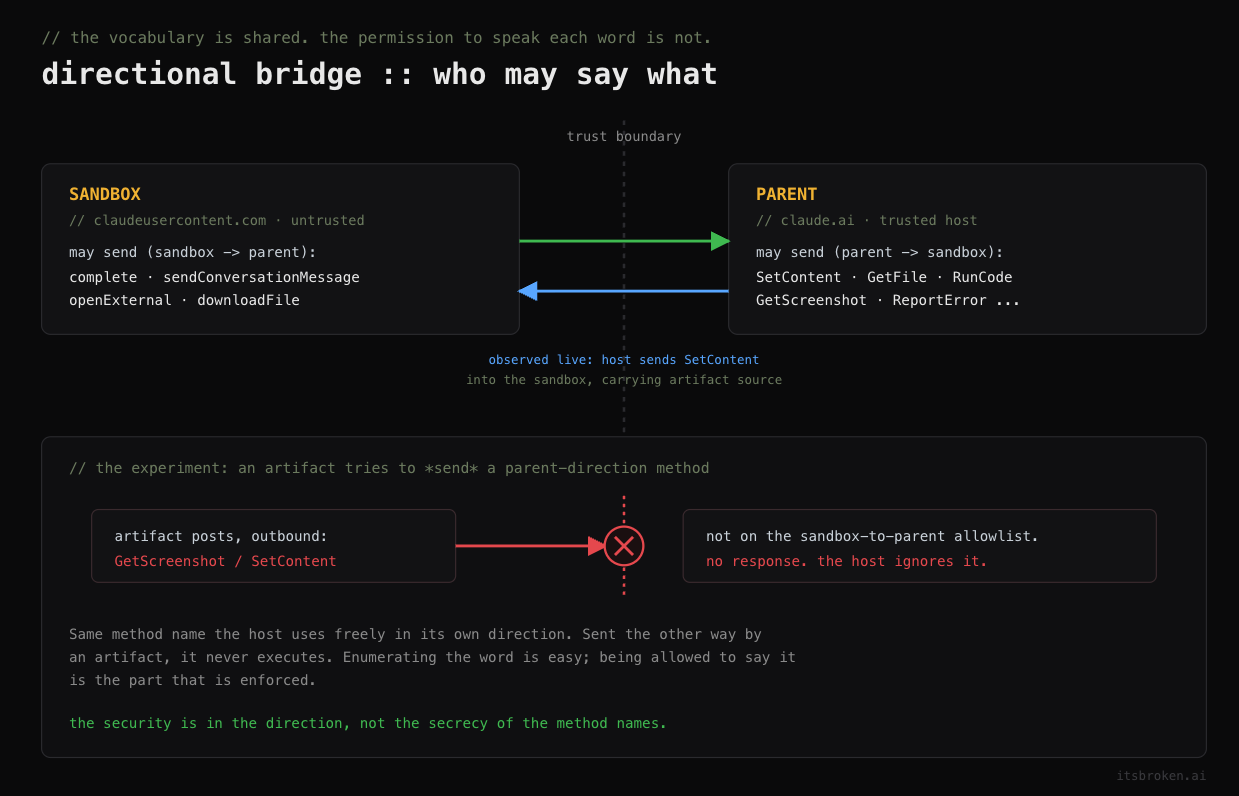
I had the arrows pointing the wrong way. The enum was not a list of privileges I could invoke; it was a bidirectional vocabulary and the security lived in the parent's refusal to execute the half of it that artifacts are not allowed to send.
So the awesome news is that the system is working as designed and there was no security bug.
Watching directionality happen
Here is the part the desktop pass added, and it's my favorite because it turned Anthropic's explanation from something I took on trust into something I got to watch in the traffic.
On desktop, with the passive listener running, the inbound side of the bridge is fully visible. Among the messages that the parent sends into the sandbox:
{ "channel": "request",
"method": "anthropic.claude.usercontent.sandbox.SetContent",
"requestId": "1781...",
"payload": { "content": "import { useState, useRef, useEffect } from ..." } }{ "type": "__sandbox_handshake__" }That is SetContent traveling parent-to-sandbox, carrying my own artifact's source as its payload exactly as the host populates the frame. Interspersed with it, repeated __sandbox_handshake__ frames establishing the communication channel. This is the directionality Anthropic described and I was watching it in realtime: SetContent is something the host says to the artifact, and what I had tried earlier was to say it back in the wrong direction, which the parent refused.
Seeing the legitimate parent-to-sandbox SetContent traffic was a clean confirmation that the method is real, it is in constant use, and it runs only in the direction the host initiates. An artifact posting the same method name outbound gets dropped. The vocabulary is shared but who gets to say what is not.
Why the non-finding is the point
As a perfectionist, a military veteran, and a security researcher, it's often tempting to treat a dead end as a failure, but I'm finally starting to learn it's not. A few things this exercise surfaced that were all worth more than a low-severity bug:
The model-selection "limitation" is structural. You cannot call Fable 5 from an artifact because selection is fixed server-side. Ask for it by name (or by any name, including a nonsense one), and the response hands you Sonnet 4.6 anyway, with a 200 and no comment. There's nothing to bypass, only a request field the server overrides. A cleaner answer than any flag-flip would have been, and a pretty funny one given how much noise the Claude Fable 5 launch was making while I failed to reach it through a Sonnet-shaped hole.
Read the response, not the status code. The investigation has two moments that look like success and are not: the desktop call that returned 200 while swapping my model, and the 200-plus-empty that looked like a screenshot and was not. Both would have produced a wrong, published claim if I had trusted the green light over the body of the response. A status code tells you the call completed, but it doesn't tell you it did what you requested.
The sandbox's isolation is layered and redundant. Origin isolation, an absent module graph, and allowlist message validation each independently blocked privilege escalation on both platforms I tested. Defense-in-depth is not a slogan here and it's evident. I watched separate mechanisms each stop the same vector.
Directionality is the quiet hero. The most important security property wasn't the undocumented method names (although I'll admit that was a pretty cool and fun find). I enumerated all of them, but ultimately from a security perspective it didn't matter. What mattered was that the parent enforces which direction each method is allowed to travel. The desktop traffic shows the host using SetContent constantly in its own direction while the parent drops the same method when an artifact sends it outbound. Knowing the vocabulary really doesn't get you anything if the host won't execute the words you aren't allowed to say. For anyone building a sandbox, this is a solid paradigm to emulate. Being stealthy about your RPC surface isn't a control, but validating the direction and origin of every message is.
Conservative disclosure protects the researcher too. Because I scoped the report to "reachable, executes, scope unconfirmed, here is the re-test," the correction landed on a hypothesis I had explicitly hedged, not on an overclaim I had tied my name to. The discipline that felt like under-selling in the moment is the same discipline that made the "working as designed" response so many researchers dread cost me nothing but time.
The boundary you couldn't break through sometimes is a more interesting story than the one you could; it tells you how the thing is actually built.
Wrapping it up
I went down this rabbit hole because a one-line question, "can I call Fable 5 from in here," haunted me. The answer turned out to be "no," and the architecture of "why not" is genuinely worth learning about. Artifacts get a fixed model decided server-side, regardless of the string you send or the platform you send it from. They talk to their host over a typed postMessage bridge. They live behind a boundary that held against cross-origin object access, module-graph theft, and forged dispatch alike. The privileged-looking methods in the client code are real, but they travel the other direction, and the desktop traffic shows the host using them exactly as designed while the parent refuses to run them when an artifact tries to send them.
None of that required me breaking anything, and the one thing that looked like it might have was a hypothesis I couldn't substantiate without crossing a line. That led to me reporting it the way I would want a finding against my own system reported. It got a precise knockdown and then I watched the desktop traffic confirm Anthropic's feedback.
If there is a takeaway beyond the technical specifics here, it's this: when you're poking at a sandbox you're allowed to poke at, the most valuable thing you can produce is an accurate "lay of the land," a map including the parts that say "firm blocker here." Enumeration can be easy, but sometimes knowing where to stop and being willing to publish a clean no is the part that builds trust on both sides of the disclosure while giving insight to the community.
Credits and references
- Anthropic "What are artifacts and how do I use them?": how AI-powered artifacts are currently described by Anthropic. https://support.claude.com/en/articles/9487310-what-are-artifacts-and-how-do-i-use-them
- Anthropic original artifacts launch announcement: primary source for the original feature, with update log. https://anthropic.com/news/claude-powered-artifacts
- Anthropic's Responsible Disclosure Policy: for anyone else hoping to submit research to Anthropic. https://anthropic.com/responsible-disclosure-policy
- Simon Willison, AI-powered apps with Claude (2025): Simon dives into "Claudeception" and artifact functionality. Documents the change from fetch to window.claude.complete(). https://simonwillison.net/2025/Jun/25/ai-powered-apps-with-claude/
Max Andreacchi (atomicchonk) studies how intelligent systems fail, drinks unreasonable amounts of caffeine, and occasionally reverse-engineers a sandbox just to find out it was built correctly. Past stops: USAF/CNMF, CrowdStrike, SpecterOps. Holds OSCP and CRTO. Powered by hyperfixations, corgis, and a refusal to leave a 200 unexamined.